功能篇
Redis 过期删除策略和内存淘汰策略
过期删除策略
- Redis 可以对 key 设置过期时间,因此需要有相应的机制将已过期的键值对删除,而过期键值删除策略就是完成这个工作的
如何设置过期时间
对 key 设置过期时间:
expire <key> <n>:设置 key 在 n 秒后过期pexpire <key> <n>:设置 key 在 n 毫秒后过期expireat <key> <n>:设置 key 在某个时间戳(精确到秒)之后过期pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)之后过期
在设置字符串时对 key 设置过期时间:
set <key> <value> ex <n>: 设置键值对的同时指定过期时间(精确到秒)set <key> <value> px <n>:设置键值对的同时指定过期时间(精确到毫秒)setex <key> <n> <value>:设置键值对的同时指定过期时间(精确到秒)
查看某个 key 的时间可以使用
TTL <key>命令
取消 key 的过期时间,可以使用PERSIST <key>命令
如何判断 key 已过期
- 当对一个 key 设置过期时间时,Redis 会把该 key 带上过期时间存储到一个过期字典(expires dict)中,过期字典中保存了数据库中所有 key 的过期时间
过期字典存储在 redisDB 结构中typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb; - 过期字典数据结构:
- 过期字典的 key 是一个指针,指向某个键对象
- 过期字典的 value 是一个 long long 类型的整数,保存了 key 的过期时间

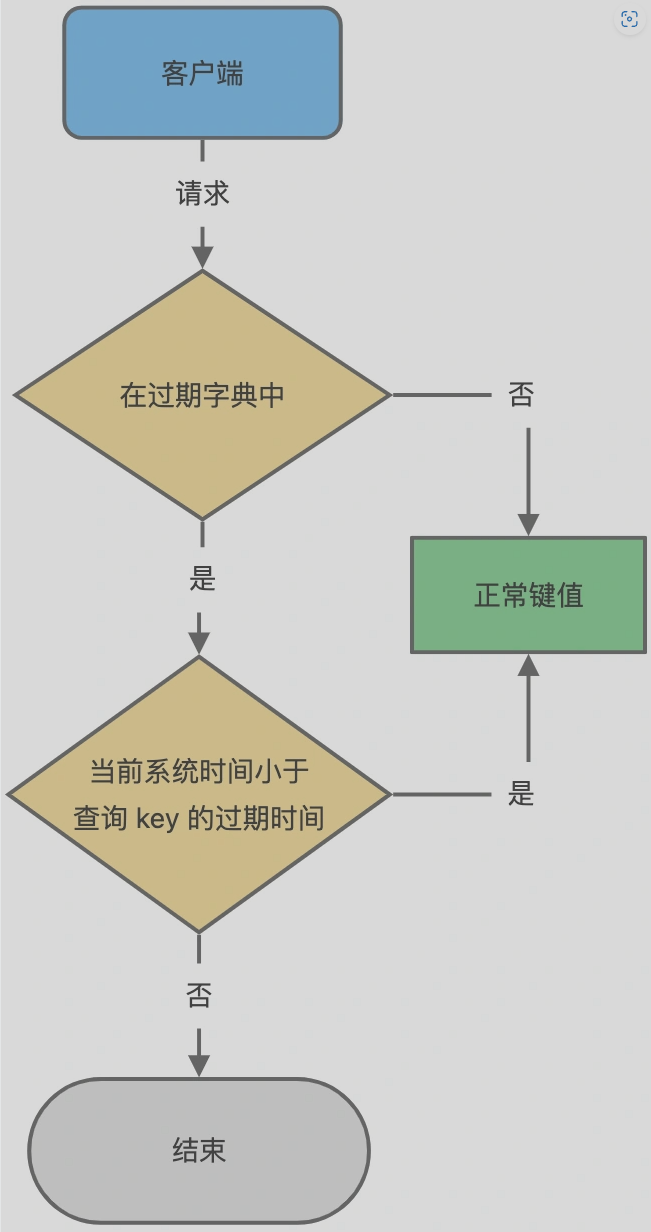
字典实际上是哈希表,可以用 O(1) 的时间复杂度来快速查找,当查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中: - 如果不在,正常读取键值
- 如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行对比,大于系统时间则没有过期,否则判断该 key 过期
过期删除策略
 过期 key 会被尽快删除,内存可以尽快释放,对内存最友好
**缺点**:过期 key 比较多的情况下,删除过期 key 可能占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,会对服务器的响应时间和吞吐量造成影响,因此对于 CPU 不友好
- 惰性删除
不主动删除过期键,每次访问 key 时都检测 key 是否过期,如果过期则删除该 key
优点:每次访问时才检查 key 是否过期,只会使用很少的系统资源,因此对 CPU 最友好
缺点:如果一个 key 已经过期,但是一直没有被访问,那就会一直保留在数据库中,占用的内存就不会释放,造成内存空间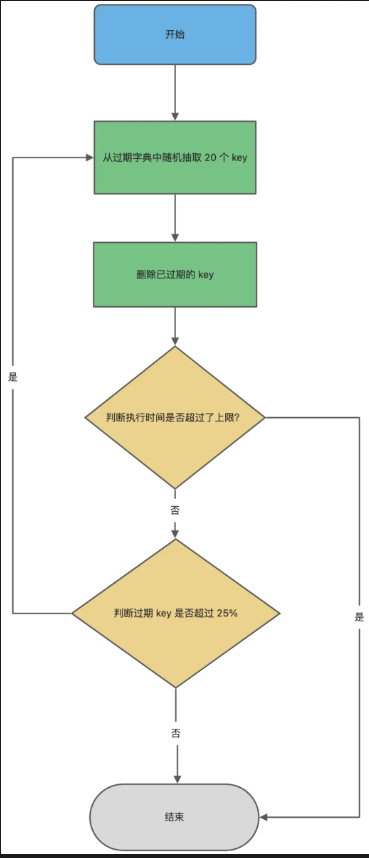 制删除操作的时长和频率减少操作对 CPU 的影响,同时也能删除一部分过期的数据,减少过期键对空间的无效占用
制删除操作的时长和频率减少操作对 CPU 的影响,同时也能删除一部分过期的数据,减少过期键对空间的无效占用
缺点:内存清理效果没有定时删除好,使用的系统资源没有惰性删除少;难以确定删除操作执行的时长和频率
Redis 使用的过期

由 db.c 文件中 expireIfNeeded 函数实现
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsE

 PIRE_CYCLE_LOOKUPS_PER_LOOP` 决定,这个数值为 20,写死在代码中
```C showLi
 抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4);
- 定期删除流程
- 从过期字典中随机抽取 20 个key
- 检查这 20 个 key 是否过期,并删除已经过期的 key
- 如果本轮检查的已过期 key 的数量超过 5 个(20/4) ,即
已过期 key 的数量占比随机抽取 key 的数量大于25%,继续重复步骤 1,如果比例小于 25%,则停止删除过期 key,等待下一轮再检查
内存淘汰策略
当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,就会使用内存淘汰策略删除符合条件的 key,来办证 Redis 高效的运行
设置 Redis 的最大运行内存
在配置文件 redis.conf 中通过参数 maxmemory <bytes> 设定最大运行内存,只有在 Redis 的运行内存达到设置的最大运行内存后才会触发内存淘汰策略,不同位数的操作系统 maxmemory 的默认值不同
- 64 位操作系统:maxmemory 默认为 0,表示没有内存大小限制,不管用户存放多少数据到 Redis 中,都不会对可用内存进行检查
- 32 位操作系统:maxmemory 默认值为 3G,因为 32 位机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源支撑运行,因此限制最大 3G,防止因为内存不足导致 Redis 实力崩溃
内存淘汰策略种类
Redis 内存淘汰策略共有 8 种,大体分为 不进行数据淘汰 和 进行数据淘汰 两类策略
不进行数据淘汰
noeviction:Redis 3.0 之后默认的内存淘汰策略,表示当运行内存超过最的设置内存时,不淘汰任何数据,这时如果有新的数据写入,则会触发 OOM,,但是如果没有数据写入,只是单纯查询或者删除,还可以正常工作进行内存淘汰
在进行内存淘汰的策略中,又可以细分为在设置了过期时间的数据中进行淘汰和在所有数据范围内进行淘汰两类策略
在设置了过期时间的数据中进行淘汰:- volatile-random:随机淘汰设置了过期时间的任意键值
- volatile-ttl:优先淘汰更早过期的键值
- volatile-lru:Redis 3.0 之前默认策略,淘汰所有设置了过期时间的键值中 最久未使用 的键值
- volatile-luf:Redis 4.0 后新增的策略,淘汰所有设置了过期时间的键值中 最少使用 的键值
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值
- allkeys-lru:淘汰所有键值中最久未使用的键值
- allkeys-lfu:Redis 4.0 之后新增的策略,淘汰所有键值中最少使用的键值
查看当前 Redis 使用的内存淘汰策略:
config get maxmemory-policy修改 Redis 内存淘汰策略
- 通过
config set maxmemory-policy <策略>命令,优点是设置后无需重启立即生效,但是重启 Redis 后设置就会失效 - 通过修改 Redis 配置文件,设置
maxmemory-policy <策略>,优点是重启 Redis 服务后配置不会丢失,但是缺点是必须重启 Redis 服务设置才能生效
- 通过
LRU 和 LFU 算法的区别
LFU 是 Redis 4.0 之后新增的内存淘汰策略,主要是为了解决 LRU 算法存在的问题
LRU 算法
传统 LRU 算法:
全称Least Recently Used,最近最少使用,会选择淘汰最近最少使用的数据
传统 LRU 算法实现是 基于链表结构 的,链表中的元素按照顺序从前到后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可
存在的问题:- 需要使用链表管理所有的缓存数据,会带来额外的空间开销
- 有数据被访问时,需要在链表上移动该数据到头部,如果有大量数据被访问,就会带来大量链表移动操作,降低 Redis 缓存性能
Redis 的 LRU 算法实现:
Redis 实现的是一种 近似 LRU 算法,目的是更好的节省内存,实现方式是在 Redis 的对象结构体中 添加额外字段用于记录此数据的最后一次访问时间,当 Redis 进行内存淘汰时会使用随机采样的方式淘汰数据,随机取 n 个值(可配置),然后淘汰最久未使用的值
优点:- 不用为所有数据维护一个大链表,节省内存空间
- 不用在每次访问数据时移动链表项,提升了 Redis 性能
存在问题:
无法解决缓存污染问题,比如应用一次性读取大量数据,但是这些数据只会被读取一次,后续会被留存在 Redis 缓存中很长一段时间,造成缓存污染(在 Redis 4.0 之后引入 LFU 算法解决)
LFU 算法
- 全称
Least Frequently Used,最近最不常用,根据数据访问次数来淘汰数据,核心思想是如果数据过去被多次访问,那么将来会被访问的频率也更高
因此 LFU 算法会记录每个数据的访问次数,这样就解决了偶尔被访问一次后数据在缓存中长时间存留的问题 - Redis 的 LFU 算法实现
LFU 相比于 LRU 多记录了 数据访问频次 的信息Redis 对象头中 24bits 的 lru 字段,在 LRU 和 LFU 算法下使用方式并不相同typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;
LRU 算法:用于记录 key 的访问时间戳,Redis 可以根据记录值来比较最后一次 key 的访问时间,从而淘汰最久未被使用的 key
LFU 算法:分成两段进行存储,高 16bits 存储 ldt(Last Decrement Time),低 8bits 存储 logc(Logistic Counter)
- ldt 用于记录 key 的访问时间戳
- logc 用于记录 key 的访问频次,值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5(logc 不是单纯的访问次数,而是频率,会随着时间推移而衰减)
每次 key 被访问时,会先对 logc 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问时间跟本次访问时间差距很大,则衰减值越大,这样实现的 LFU 算法是根据访问频率对数据进行淘汰,而非单纯的访问次数
Redis 在访问 key 时,logc 是这样变化的: 先按照上次访问时间距离当前的时长对 logc 进行衰减,再按照一定概率增加 logc 的值
redis.conf 提供两个配置项用于调整 LFU 算法从而控制 logc 的增长和衰减:- lfu-decay-time 用于调整 logc 的衰减速度,是一个以分钟为单位的数值,默认为 1,值越大衰减越慢
- lfu-log-factor 用于调整 logc 的增长速度,值越大增长越慢