Redis 常见数据类型和应用场景
五种常见数据类型
其他数据类型
BitMap
- 位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap 通过最小的单位 bit 进行
0|1的设置,表示某个元素的状态或者值,时间复杂度为O(1)
由于 bit 是计算机中最小的单位,用于存储非常节省空间,因此适用于 数据量大且使用二值统计 的场景
- 内部实现
BitMap 本身使用 String 类型作为底层数据结构实现,用于 二值统计状态,String 类型会保存为 二进制的字节数组,因此可以将 BitMap 看成一个 bit 数组 - 应用场景
- 签到打卡
使用 0|1 记录签到状态,每个用户一天的迁到主需要一个 bit 位就能表示,一年只需要 365 个 bit 位
用户 ID 100,2022年6月份签到情况:SETBIT uid:sign:100:202206 2 1 //用户在 2022-6-3 签到GETBIT uid:sign:100:202206 2 //用户在 2022-6-3 是否签到BITCOUNT uid:sign:100:202206 //统计用户6月份签到次数BITPOS uid:sign:100:202206 1 //用户6月份首次打卡日期
- 判断用户登录态
BitMap 提供GETBIT、SETBIT操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作
只需要一个key=login_status表示存储用户登陆状态集合数据,将用户 ID 作为 offset,在线状态设置为 1,通过GETBIT判断用户是否在线(5000W 用户只需要 6MB 空间)SETBIT login_status 10086 1 //ID=10086 的用户已登陆GETBIT login_status 10086 //判断用户是否登陆SETBIT login_status 10086 0 //登出,将用户对应 offset 的 value 设置为 0
- 连续签到用户总数例如统计连续 7 天打卡的用户总数
把每天的日期作为 BitMap 的 key,userId 作为 offset,打卡则将 offset 位置的 bit 设置为 1
一共有 7 个 BitMap 代表 7 天,对 7 个 BitMap 对应的 bit 位做 与运算,将结果保存到一个新的 BitMap 中,再通过BITCOUNT统计bit=1的个数就得到了连续打卡 7 天的用户总数
Redis 提供了BITOP operation destkey key [key ...]指令用于对一个或多个 key 的 BitMap 进行位元操作# 统计连续 3 天打卡的用户数
# 与操作
BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
# 统计 bit 位 = 1 的个数
BITCOUNT destmap
- 签到打卡
HyperLogLog
- Redis 2.8.9 版本新增的数据类型,用于 统计基数 的数据集合类型,但 HyperLogLog 的统计规则是基于概率完成的,不是非常准确,标准误算率为 0.81%
统计基数: 指统计一个集合中不重复的元素个数 - 优点 1-24
在输入元素的数量或者体积非常大的时候,计算基数所需的内存空间总是 固定的 并且是 很小的
在 Redis 中每个 HyperLogLog 键只需要花费 12kb 的内存就可以计算接近 2^64 个不同元素的基数,和元素越多越耗费内存的 Set 和 Hash 相比,HyperLogLog 非常节省空间 - 应用场景
- 百万级网页 UV 统计
统计 UV 时可以使用 PFADD 命令把访问页面的每个用户都添加到 HyperLogLog 中PFADD page1:uv user1 user2 user3 user4 user5
然后就可以使用 PFCOUNT 命令 直接获得 page1 的 UV 值了PFCOUNT page1:uv
HyperLogLog 给出的统计结果存在一定误差,如果需要精确统计结果的话,最好还是使用 Set 或者 Hash 类型
- 百万级网页 UV 统计
GEO
- Redis 3.2 新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作
LBS(Location-Based Service):基于位置信息服务,LBS 应用访问的数据是和人或物相关联的一组经纬度信息,而且需要能查询相邻的经纬度范围,GEO 非常适合应用在 LBS 服务的场景中 - 内部实现
GEO 本身没有设计新的底层数据结构,而是直接使用 Sorted Set 集合类型
GEO 使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,其中的两个关键机制就是 对二维地图做区间划分 和 对区间进行编码。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数
这样就可以把经纬度保存在 Sorted Set 中,利用 Sorted Set 提供的 按权重进行有序范围查询 的特性来实现 LBS 中频繁使用的搜索附近的需求 - 应用场景
- 滴滴叫车
假设车辆 ID 为 33,经纬度位置为 (116.034579, 39。030452),可以使用一个 GEO 集合保存所有车辆的经纬度,集合的 key 是 cars:locationsGEOADD cars:locations 116.034579 39.030452 33 //把 ID=33 的车辆当前经纬度存入 GEO 集合中GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10 //查询以用户经纬度为中心的 5 公里内的车辆信息
- 滴滴叫车
Stream
是 Redis 5.0 版本新增的数据类型,专门为消息队列设计
在 Stream 出现之前,Redis 消息队列的实现方式都存在各自的缺陷:- 发布订阅模式,不能持久化,也就无法可靠的保存消息,并且离线重连的客户端不能读取历史消息
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一ID
Stream 类型可以完美实现消息队列,支持消息的持久化、自动生成全局唯一ID、支持 ACK 确认消息的模式、支持消费组模式等,让消息队列更加稳定和可靠
应用场景
- 消息队列
- 如果想要实现阻塞读(当没有数据时阻塞住),可以调用 XREAD 时设置 BLOCK 配置项,类似于 BRPOP 的阻塞读取操作
# $ 符号表示读取最新的消息,10000 的单位是 ms,表示 XREAD 在读取最新消息时如果没有消息到来,阻塞 10S 再返回
XREAD BLOCK 10000 STREAMS mymq $ - Stream 可以使用 XGROUP 创建消费组,创建消费组后,Stream 可以使用 XREADGROUP 命令让消费组内的消费组读取消息,同一个消费组内的消费者不能消费同一条消息,但是不同消费组内的消费者可以消费同一条消息(但是有前提条件,创建消费组的时候,不同消费组指定了相同位置开始读取消息)
- 如何保证消费者在发生故障或宕机重启后仍然可以读取为处理完的消息
Stream 会自动使用内部队列(PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Stream 消息处理完成
如果消费者没有成功处理消息,就不会给 Stream 发送 XACK 消息,消息仍会留存,此时消费者可以在重启后使用 XPENDING 命令查看已读取但未确认处理完陈给的消息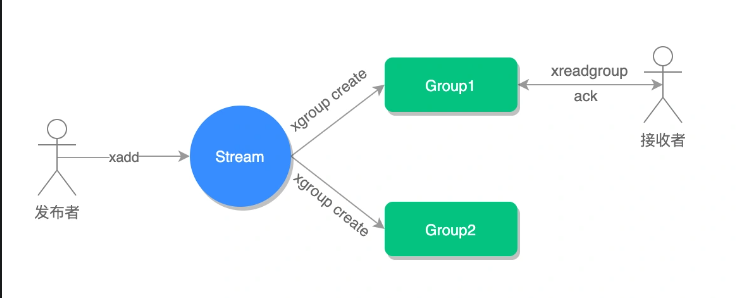
- 总结
- 消息保序:XADD/XREAD
- 阻塞读取:XREAD block
- 重复消息处理:Stream 在使用 XADD 时会自动生成全局唯一 ID
- 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息消费完成
- 支持消费组形式消费消息
- 如果想要实现阻塞读(当没有数据时阻塞住),可以调用 XREAD 时设置 BLOCK 配置项,类似于 BRPOP 的阻塞读取操作
- 消息队列
Stream 和专业消息队列的差距
消息不丢失
消息队列的使用分为三大块:生产者、队列中间件、消费者,保证消息不丢失就是保证三个环节都不能丢失数据
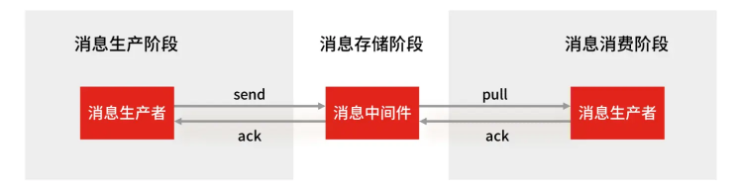
- 生产者:生产者是否丢失数据取决于对异常情况的处理是否合理,从消息被生产出来提交给 MQ 的过程中,只要能正常收到 MQ中间件的 ACK 确认响应,就表示发送成功,因此只要处理好返回值和异常,如果返回异常则进行重发,就能保证这个阶段消息不丢失
- 消费者:Stream 会自动使用内部队列(PENDING List)留存消费组中每个消费者读取但是未被确认的消息,消费者可以在重启后重新进行读取,消费成功后再发送 XACK 确认,也能保证消息不丢失
- Redis 中间件:Redis 在以下两个场景中都会导致数据丢失
- AOF 持久化配置为每秒写盘,但是写盘过程是异步的,Redis 宕机时存在数据丢失的可能
- 主从复制也是异步的,主从切换时也存在数据丢失的可能
因此 Redis 在队列中间件环节无法保证数据不丢失,而 RabbitMQ 和 Kafka 等专业的队列中间件部署时都 采用集群,生产者发布消息时队列中间件通常会 写入多个节点,也就是有多个副本,即使某个节点挂掉,也能保证数据不丢失
消息可堆积
Redis 的数据都存储在内存中,意味着一旦发生消息挤压,会导致 Redis 内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险
因此 Redis 的 Stream 提供了可以指定队列最大长度的功能,避免此类情况的出现
当指定队列的最大长度时,队列长度超出上限后旧消息会被删除,只保留固定长度的新消息,因此 Stream 在消息积压时,如果指定了最大长度,也可能丢失消息
但 RabbitMQ、Kafka 等专业队列中间件的数据都是存储在磁盘上的,当消息积压时,无非多占用一些磁盘空间
因此使用 Redis 作为队列使用可能面临的问题有:数据丢失、消息积压时的内存资源紧张
如果业务场景足够简单,对于数据丢失不敏感,且消息积压概率比较小的情况下,可以使用 Redis 作为队列中间件Redis 发布/订阅机制为什么不可以作为消息队列使用
发布订阅机制没有基于任何数据类型实现,所以不具备数据持久化能力,即不会写入 RDB 和 AOF 文件,当 Redis 宕机时数据会全部丢失
发布订阅模式是
发后既忘的工作模式,如果有订阅者离线,重连之后不能消费之前的历史数据消费端有一定的消息积压时,如果超过 32M 或者 60S 内持续保持在 8M 以上,消费端会被强行断开,这个参数在配置文件中设置,默认值
client-output-buffer-limit pubsub 32mb 8mb 60因此发布订阅模式只适用于即时通讯的场景,比如 构建哨兵集群