五大value类型
常见的数据类型:string、list、set、zset、hash
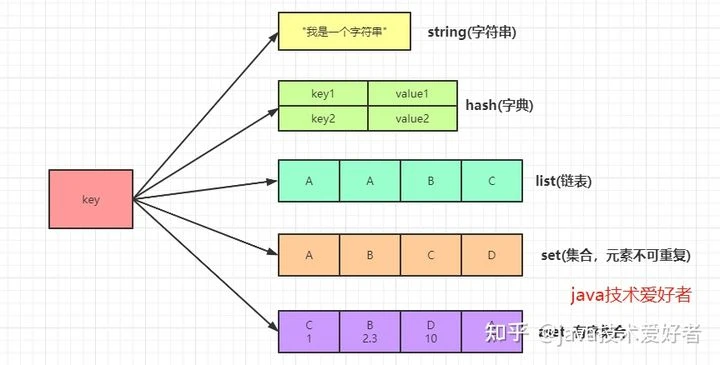
redisObject:这些数据结构在底层都是使用 redisObject 来进行表示的,redisObject 有三个重要的属性:type、encoding、ptr
- encoding:表示保存的 value 的编码
- ptr:指针,指向实际保存的 value 的数据结构
- type:表示 value 的类型
数据类型和编码方式是有一定关系的,所以数据类型和编码方式可以确定底层采用什么数据结构存储数据
string
Redis 中最常用的数据类型,字符串对象的 encoding 有三种:int、raw、embstr
- 保存整数值时会将整数值转换成 long 保存在 ptr 中,并将字符串对象的编码设置为 int

- 保存的字符串长度 <= 32字节 时,使用 SDS 保存,并将对象编码设置为 embstr

- 字符串长度 > 32字节 时,使用 SDS 保存,并将对象编码设置为 raw

- 保存整数值时会将整数值转换成 long 保存在 ptr 中,并将字符串对象的编码设置为 int
embste 和 raw 的区别
embstr 通过一次内存分配函数分配一块连续的内存空间保存 redisObject 和 SDS
raw 会通过调用两次内存分配函数来分别分配两块空间保存 redisObject 和 SDS
优点- embstr 编码将创建字符串对象所需的内存分配从 raw 编码的两次降低为一次
- 释放 embstr 编码的字符串对象同样只需要调用一次内存释放函数
- embstr 编码的字符串对象的所有数据保存在一块连续的内存中,可以更好的利用 CPU 缓存提高性能
缺点
- 如果字符串的长度增加需要重新分配内存时,整个 redisObject 和 SDS 都需要重新分配空间,所以 embstr 编码的字符串对象实际上是只读的,Redis 没有为 embstr 编码的字符串编写任何修改程序,当对象 embstr 编码的字符串对象执行修改命令时(比如 append),程序会先将对象的编码从 embstr 转换为 raw 然后再执行修改命令
string 底层存储使用的不是C语言的字符串类型,而是 Redis 自己开发的一种数据类型 SDS(Simple Dynamic String) 进行存储,是一种动态字符串
结构
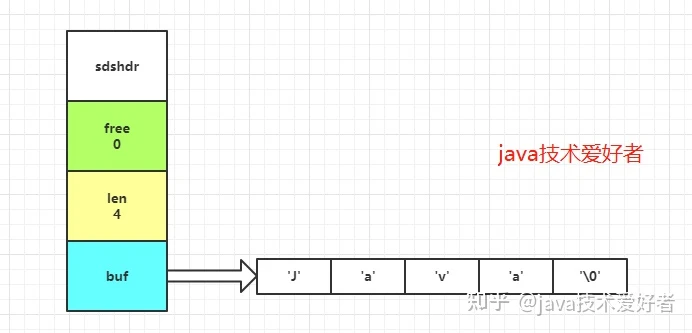
struct sdshdr{
int len;/*字符串长度*/
int free;/*未使用的字节长度*/
char buf[];/*保存字符串的字节数组*/
}SDS 的特点:
- 使用 len 属性记录字符串长度,时间复杂度为
O(1) - 修改时会先检查空间是否满足大小,不满足则会进行扩容,避免缓冲区溢出
- 空间预分配,需要进行扩展时,Redis 会为 SDS 分配好内存,并按照分配多余的 free 空间,避免连续操作字符串带来的内存分配的消耗
- 惰性释放,如果需要缩短字符串,不会立即回收多余空间,而是使用
free进行记录,等待下次扩展时使用,避免了再次进行内存分配的消耗 - 二进制安全,使用 len 记录字符串的长度,避免了在字符串中使用
\0的问题
- 使用 len 属性记录字符串长度,时间复杂度为
应用场景
- 缓存对象、常规计数、分布式锁、共享 Session 信息
list
- 列表的存储结构使用的是双向链表而非数组,随机定位性能弱,首尾插入删除性能优
- 可以从头、尾进行元素的追加、移除,可以作为队列、堆栈使用
- 编码有两种
- ziplist(压缩列表):长度小于512,并且所有元素长度都小于64字节时使用,是一块连续的内存存储,所有元素紧挨着存储
- linkedlist:长度大于512时使用,类似于 Java 中的 linkedList,插入与删除效率高,时间复杂度为 O(1)
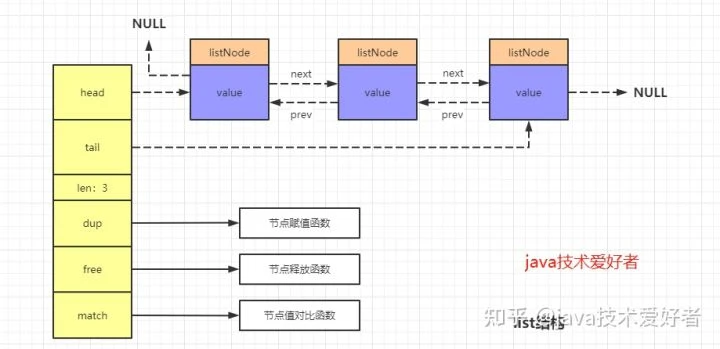
- Redis 3.2 之后 List 数据类型底层结构之用 quicklist 实现,替代里双向链表和压缩列表
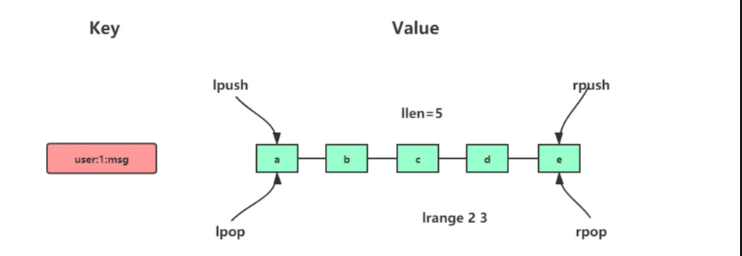
- 应用场景
消息队列
- 消息保序需求
List 本身按照先进先出的顺序对数据进行存取,可以满足消息保序的需求,使用LPUSH + RPOP或RPUSH + LPOP命令实现消息队列
生产者往 List 中写入数据时 List 并不会主动通知消费者,因此无论有没有消息写入,消费者都需要在程序中不断调用 RPOP 命令,会有性能损耗,是一个存在的风险点。可以使用 Redis 提供的 BRPOP (阻塞式读取)命令,客户端在没有读到队列数据时自动阻塞,直到有新数据写入队列再开始读取,避免消费者不断调用 RPOP,节省 CPU 开销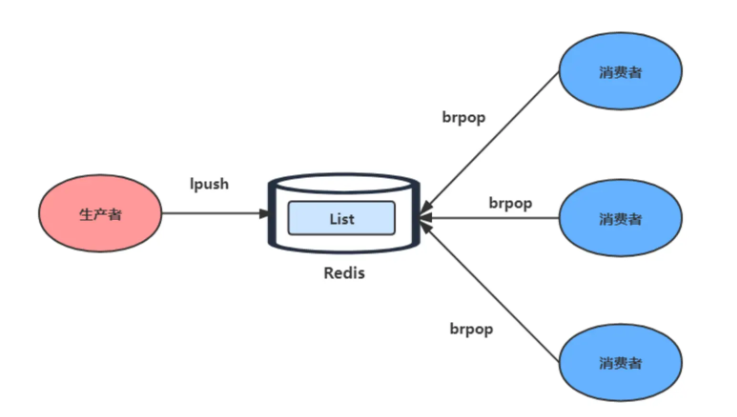
- 处理重复消息
实现重复消息判断的要求:每个消息要有一个 全局唯一ID,消费者要记录已经处理过的消息ID,用于判断消息是否已经处理
List 不会为每个消息生成 ID,因此需要为每个消息手动生成一个 全局唯一ID - 保证消息可靠性
List 类型提供了 BRPOPLPUSH 命令,作用是让消费者程序从一个 List 中读取消息的同时把这个消息插入另一个 List(备份 List) 中留存,一旦消费者读了消息但没有正常处理,可以从备份 List 中重新读取并处理
- 消息保序:使用 LPUSH + RPOP
- 阻塞读取:使用 BRPOP
- 重复消息处理:生产者自行实现全局唯一ID
- 消息可靠性:使用 BRPOPLPUSH
缺陷: 不支持多个消费者消费同一条信息,即不支持消费组的实现 (Redis 5.0 之后提供的 Stream 可以满足消息队列的三大需求并支持消费组实现)
- 消息保序需求
hash
- 采用二维结构实现,第一维是数组,第二维是链表。链表中存放 hash 的内容 key 和 value,数组里存放链表的头指针
- 通过 key 查找元素时,计算 key 的 hashcode,使用 hashcode 对数组长度进行取模定位到链表的表头,对链表进行遍历获取到相应的 value
- 编码有两种
- ziplist:哈希对象保存的键值对数量小于512,并且所有键值对的长度都小于64字节时使用
- hashtable:与 Java 中的 HashMap 类似,通过数组+链表的方式解决部分哈希冲突
- 在 Redis 7.0 后 压缩列表已经废弃,使用
listpack结构实现
rehash(扩容与缩容)
- 哈希标保存的键值对太多或者太少时
- 扩容(缩容操作则相反):
- 基于原哈希表创建一个大小等于
ht[0].used * 2n的哈希表(根据原哈希表已使用的空间扩大一倍) - 使用哈希算法重新计算索引值,然后把键值对从原哈希表拷贝到新哈希表中
- 所有键值对迁移完成后释放原哈希表内存空间
- 基于原哈希表创建一个大小等于
- 扩缩容规则:
- 服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF(持久化) 命令,且负载因子大于等1时,扩容,负载因子大于等于5时,缩容
- 负载因子 = 哈希表已保存节点数量 / 哈希表大小
渐进式 rehash
- 防止大量键值对一次性进行 rehash 导致 Redis 性能下降
- 过程
- rehash 时使用 rehashidx 字段保存迁移进度,0表示迁移开始
- 迁移过程中 ht[0] 和 ht[1] 同时保存数据,ht[0] 指向旧哈希表,ht[1] 指向新哈希表,每次对 hash 进行增删改查操作的同时,会顺便把 ht[0] 中的元素迁移到 ht[1] 中(即使没有执行操作,Redis 也会通过定时任务判断 rehash 是否完成,没有完成则继续进行)
- 当 ht[0] 中所有元素迁移到 ht[1] 中时, rehashidx 被设为-1,表示迁移完成
- rehash 完成后,ht[0] 指向的旧表会被释放,然后把新表的持有权交给 ht[0],再重置 ht[1] 指向 NULL
- 优缺点
- 优点:把 rehash 操作分散到每一个 hash 操作以及定时函数上,避免一次性集中式 rehash 带来的服务器压力
- 缺点:rehash 期间需要使用两个 hash 表,占用内存较大
set
无序、不重复,set 结构内部实现使用 hash 结构,与 Java 中 HashSet 类似,所有的 value 都指向同一个内部值
编码有两种
hashtable:见前文 hash 类型
intset:如果 value 可以转成整数值,并且长度不超过 512 字节,则使用 intset 编码
- encoding:INTSET_ENC_INT16、INSET_ENC_INT32、INSET_ENC_INT64 三种,代表整数值的取值范围,Redis会根据添加的元素大小,选择不同的类型进行存储,尽可能节省内存空间
- length: 记录集合元素个数,因此获取元素个数的时间复杂度为 O(1)
- contents:存储数据的数组,按照从小到大有序排列,不包含重复项
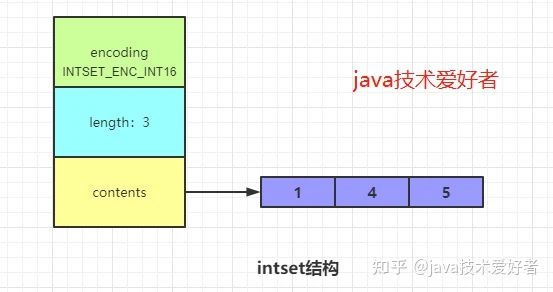
- intset 的取值范围升级:首先根据新元素的类型扩展数组 contents 的空间,然后从尾部把数据插入,最后根据新的编码格式重置之前的值,因为此时的 contents 存在两种编码的值,因此从插入数据的位置(尾部)开始,从后往前(防止数据被覆盖)将之前的数据按照新的编码格式进行移动和设置
- 升级的优点在于根据存储的数据大小选择合适的编码方式,节省内存,缺点是会带来系统资源的消耗,且升级不可逆
应用场景
数据去重、保障数据唯一性、统计多个集合交、并、差集
Set 的交、并、差集计算复杂度较高,数据量较大时可能导致 Redis 实例阻塞,可以选择 从库完成聚合计算 或者 由客户端完成聚合计算 来避免
点赞、共同关注、抽奖活动
sortedset(zset,有序集合)
- 与 set 类似,多了一个 score 属性
- 一方面等价于 Java 中的 HashMap(String, Double),可以给每一个元素赋予一个权重 score,另一方面类似于 TreeSet,内部元素会按照权重进行排序,可以得到每个元素的名次,也可以根据 score 的范围获取元素列表
- 底层实现采用两种数据结构
- ziplist:zset 长度小于128,且所有元素的长度小于64字节时使用
- skiplist(跳跃表):因为要支持随机的插入和删除,所以不适合使用链表,使用跳表实现,查询的时候可以减少时间复杂度,类似于二分查找,时间复杂度为 O(logN)
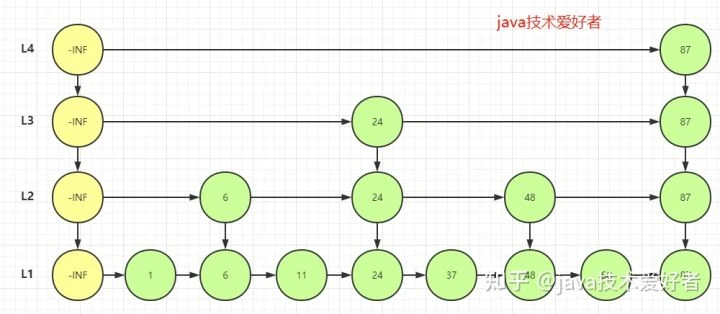
- Redis 7.0 中压缩列表废弃,使用 listpack 实现
- 应用场景
排行榜、电话/姓名排序