11-15
11 | 万金油的String,为什么不好用了
- String类型可以保存二进制字节流,只要把数据转换成二进制字节数组,就可以保存任意类型的数据
- String类型保存数据时消耗的内存空间比较多
- 简单动态字符串(Simple Dynamic String,SDS): 在String类型保存的数据中包含字符时使用
- buf: 字节数组,保存实际数据,为表示字节数组的结束,Redis会自动在数组最后加一个"\0",这回额外占用一个字节的开销
- len: 占4个字节,表示buf的已用长度
- alloc: 占4个字节,表示buf的实际分配长度,一般大于len
- 某些场景下可用集合,采用二级编码的方式保存数据,因为集合类型有非常节省内存空间的底层实现结构
- Hash类型使用两种底层实现结构,一种是压缩列表,一种是哈希表,默认使用压缩列表,在超过两个阈值时使用哈希表
- Hash类型底层实现切换的两个阈值:
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
12 | 有一亿个keys要统计,应该用哪种集合?
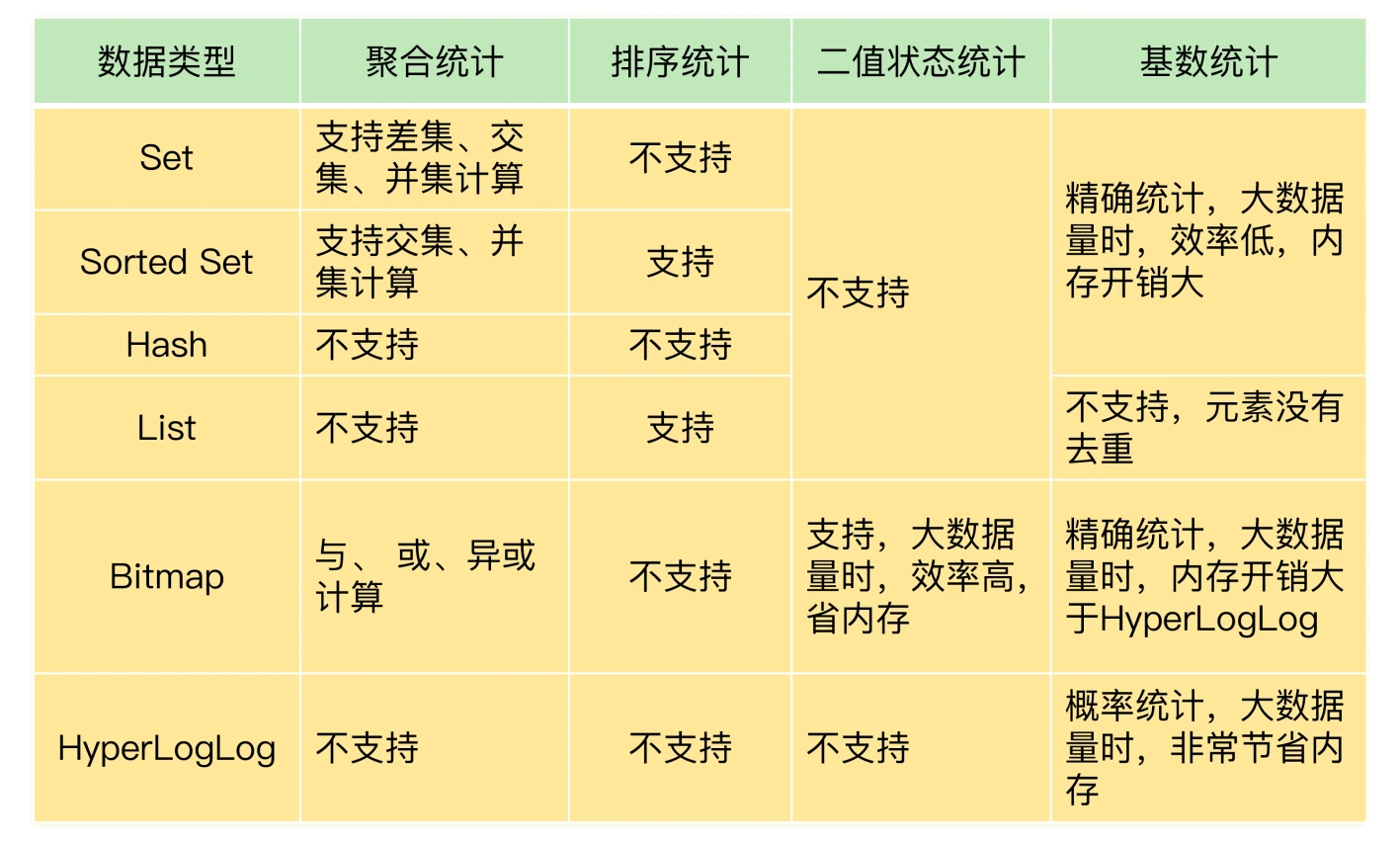
- 统计模式下Set、Sorted Set、Hash、List、Bitmap、HyperLogLog 的支持情况和优缺点
- 常用的集合统计模式
- 聚合统计: 统计多个集合元素的聚合结果(交集、并集、差集)
- 统计用户留存量: key使用 user🆔当天时间戳,value为Set集合,记录当天登陆用户ID,再添加一个Set用于记录累计用户
每日用户Set和累计用户Set的差集为新增用户,交集为留存用户,并集为累计用户
计算量较大情况下可能导致实例阻塞,可从主从集群中选择一个从库专门负责聚合计算,或者在客户端读取数据进行计算
- 排序统计: 比如最新评论列表,要求集合类型能对元素保序,使用List或者Sorted Set,List根据插入顺序排序,在数据更新频繁时分页可能获取到旧元素,Sorted Set根据权重排序,推荐在数据频繁更新并且需要分页时使用
- 二值状态统计: 指集合元素的取值就只有 0 和 1 两种,比如签到打卡、商品是否存在、用户是否在线等场景,只用一个bit表示0或1,记录海量数据时能有效节省内存空间
Bitmap: 使用String类型作为底层数据结构实现的一种统计二值状态的数据类型,支持多个Bitmap进行安慰做"与"、"或"、"异或"操作 - 基数统计: 指统计一个集合中不重复的元素个数,比如统计网页UV
网页UV统计: 可以使用Hash类型,当页面数量大时会消耗较多内存空间,推荐使用HyperLogLog
HyperLogLog: 用于统计基数的数据集合类型,当集合元素数量非常多时,计算基数所需的空间总是固定且小的,但是统计规律基于概率,统计结果有一定误差,标准误差率为0.81%,要求精确统计结果时,仍使用Hash或者Set
13 | GEO是什么?还可以定义新的数据类型吗?
- LBS(Location-Based Service,LBS): LBS应用访问的数据是和人或物关联的一组经纬度信息
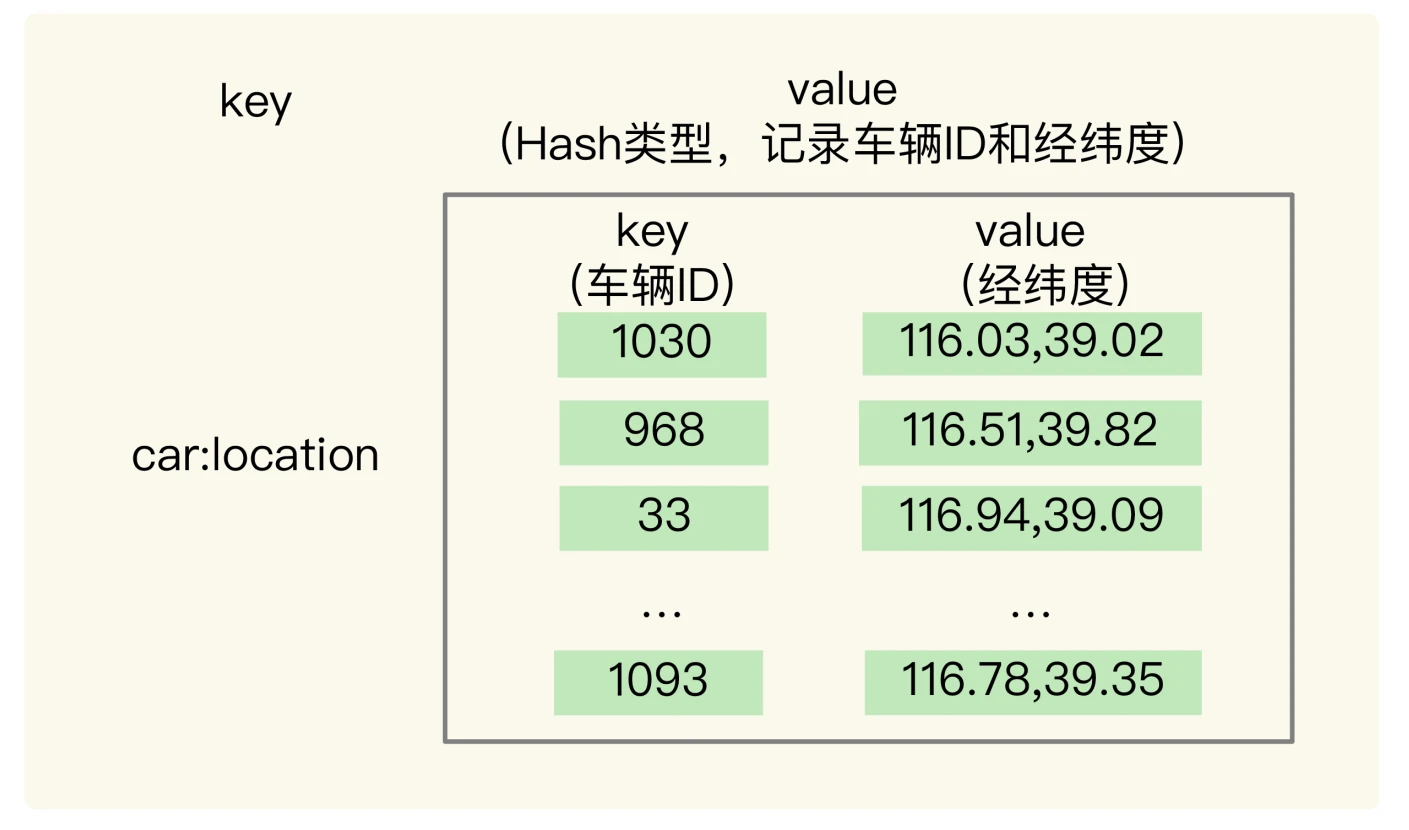
- GEO: 使用Sorted Set实现
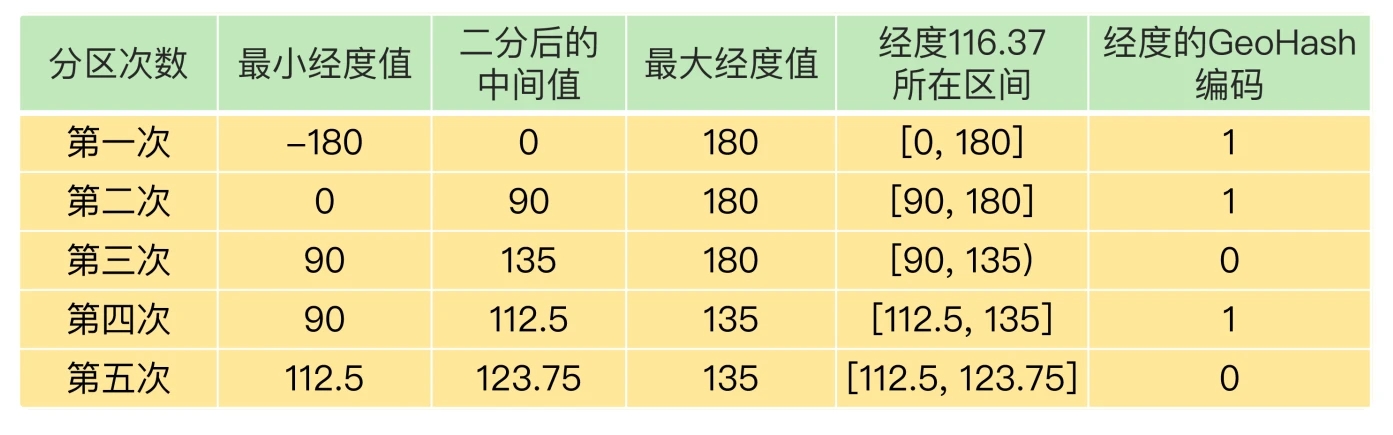
- GeoHash编码: 二分区间,区间编码
14 | 如何在Redis中保存时间序列数据?
- 时间序列数据:
- 写: 高并发写入,主要为插入数据,基本不进行更新,要求选择的数据类型在插入时复杂度低,尽量不阻塞
- 读: 复杂查询,查询模式多(单点查询、范围查询、聚合计算)
- 单点查询: 根据一个时间戳,查询相应时间的数据
- 范围查询: 查询起始和截止时间戳范围内的数据
- 聚合计算: 针对起始和截止时间戳范围内的所有数据进行计算,例如求最大/最小值、均值等
- 实现方案:
- 基于Hash和Sorted Set保存时间序列数据
- 优点: redis内在数据类型,代码成熟性能稳定,系统稳定性较高
- 使用Hash类型支持单点查询,但不支持范围查询,同时使用Sorted Set类型存储时间序列数据,把时间戳作为元素分数,以支持范围查询
- 同时写入Hash和Sorted Set的原子性操作保证: 使用Redis的简单事务(Redis事务不是完整的事务,当有一个命令失败时还是会继续往下执行)

- 聚合计算功能: 将时间范围内数据取回客户端自行完成聚合计算,大量数据在Redis和客户端之间频繁传输,会和其他操作命令竞争网络资源,导致其他操作变慢
- 基于RedisTimeSeries模块保存时间序列数据
- 不属于Redis内建功能模块,需要自行编译成动态链接库,使用loadmodule命令进行加载
- 底层数据结构使用链表,范围查询复杂度是O(N),TS.GET命令查询只能返回最新数据,无法像方案1一样返回任意时间点数据
15 | 消息队列的考验:Redis有哪些解决方案?
消息队列的存取需求
- 基于消息队列的组件通信:
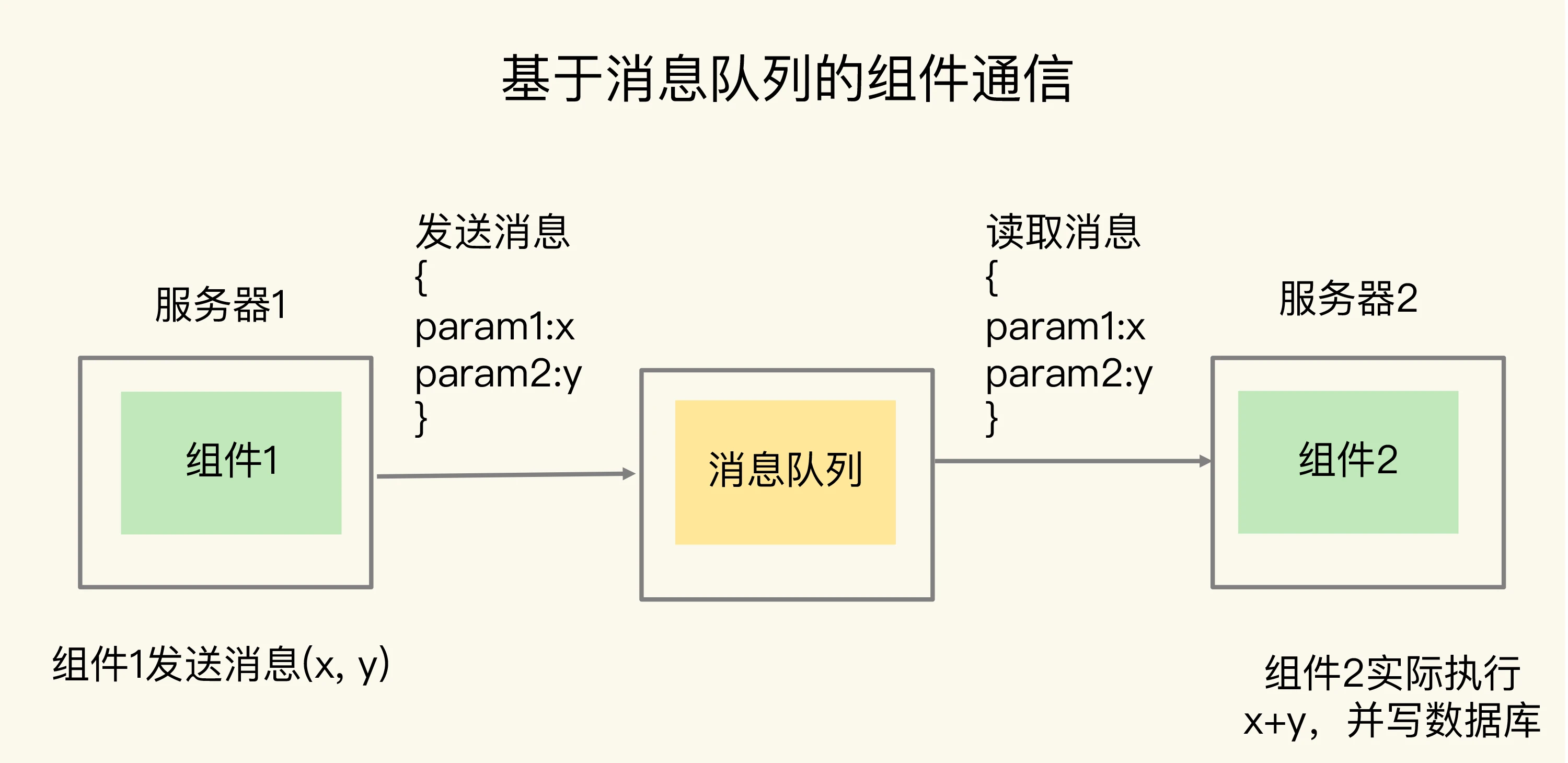
- 通用消息队列架构模型:
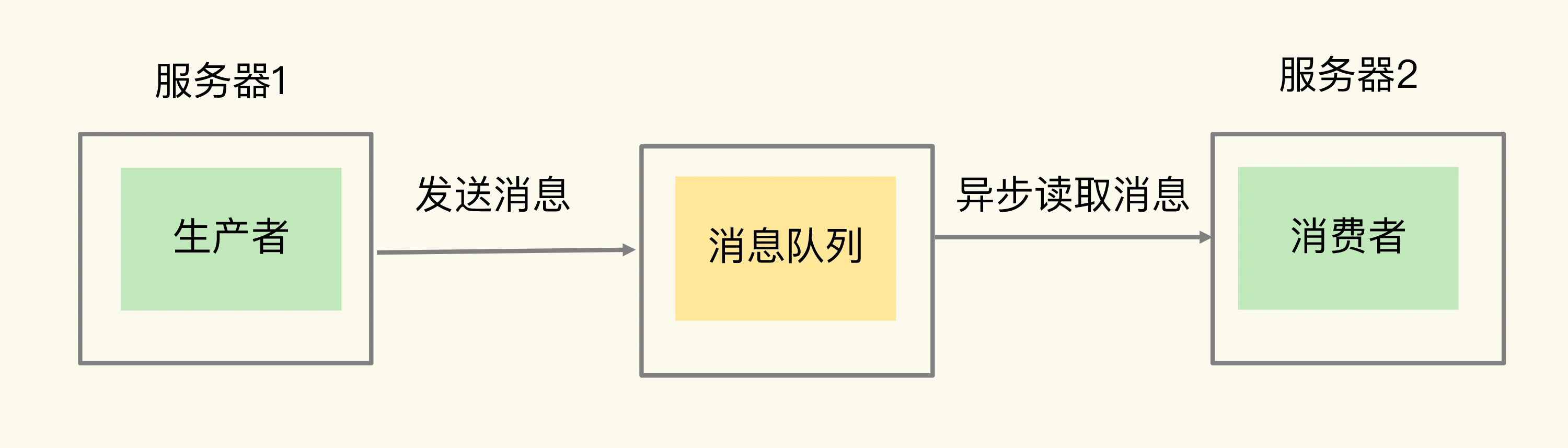
- 使用消息队列作为分布式组件通信的优势: 使用消息队列时,消费者可以异步读取生产者信息,然后再进行处理,这样即便生产者发送消息的速度远远超过消费者处理消息的速度,生产者已经发送的消息也可以缓存在消息队列中,避免阻塞生产者
- 消息队列在存取消息时必须要满足的三个需求: 消息保序、处理重复的消息、保证消息可靠性,
Redis的List和Streams两种数据类型都可以满足这三个需求- 消息保序: 虽然消费者是异步处理消息,但是消费者仍然需要按照生产者发送消息的顺序来处理消息,避免后发送的消息被先处理,对于要求消息保序的场景来说,消息乱序处理可能导致业务逻辑错误执行,从而造成损失
- 重复消息处理: 消费者从消息队列读取消息时,有可能因为网络堵塞而出现消息重传的情况,消费者可能受到多条重复的消息,可能造成一个业务逻辑被多次执行
- 消息可靠性保证: 消费者在处理消息的时候,有可能因为故障或者宕机导致消息没有处理完成,因此消息队列需要提供消息可靠性的保证,即当消费者重启后,也可以重新读取消息再次进行处理,避免消息漏处理的情况
基于List的消息队列解决方案
- 消息保序
List本身按照先进先出的顺序对数据进行存取。生产者使用LPUSH命令把要发送的数据依次写入List,消费者则可以使用RPOP命令从List中按照写入顺序依次读取消息进行处理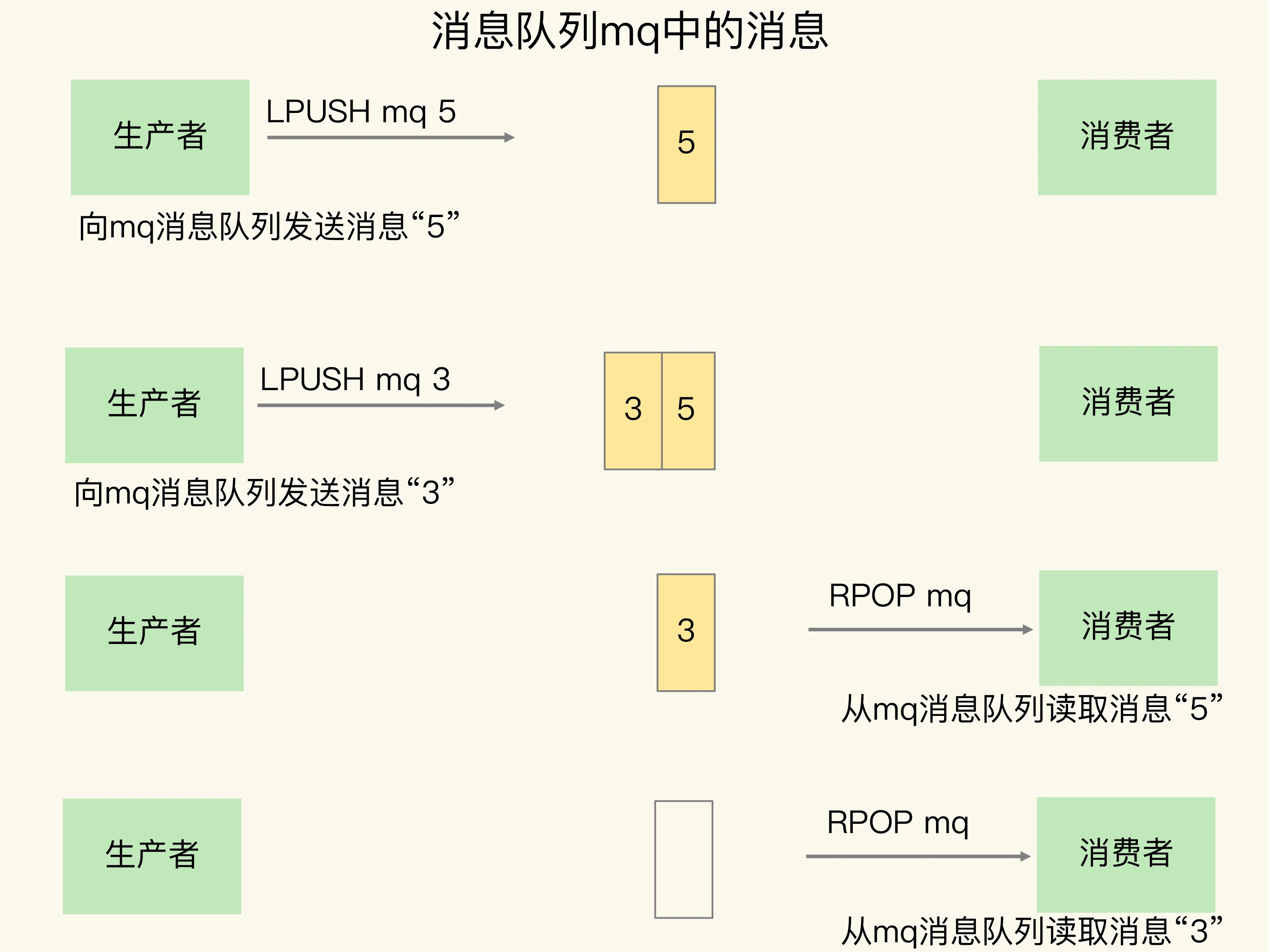
潜在性能风险点: 生产者往List中写入数据时并不会主动通知消费者,因此消费者需要不断调用RPOP命令才能保证及时处理消息,因此即使没有新消息写入,消费者也要不停的调用RPOP命令,这样会导致消费者的 CPU 和内存的浪费
解决方案:Redis提供了BRPOP命令,成为阻塞式读取,客户端在没有读到队列数据时,会自动阻塞,知道有新的数据写入队列,在开始读取新数据 - 重复消息判断
List本身并不会为每个消息生成 ID 号,因此消息的全局唯一 ID 号需要由生产者在发送消息前自行生成,生成后在把消息插入List时要把生成的 ID 包含在消息中 - 消息可靠性保证
当消费者从List中读取一条信息后,List就不会再留存这条消息,为了留存消息,List类型提供了BRPOPLPUSH命令,作用是让消费者程序从一个List中读取消息,同时Redis会把这条消息再插入另一个List(备份 List) 中留存,这样即使消费者读取消息后没有正常进行处理,也可以从备份List中重新读取消息并进行处理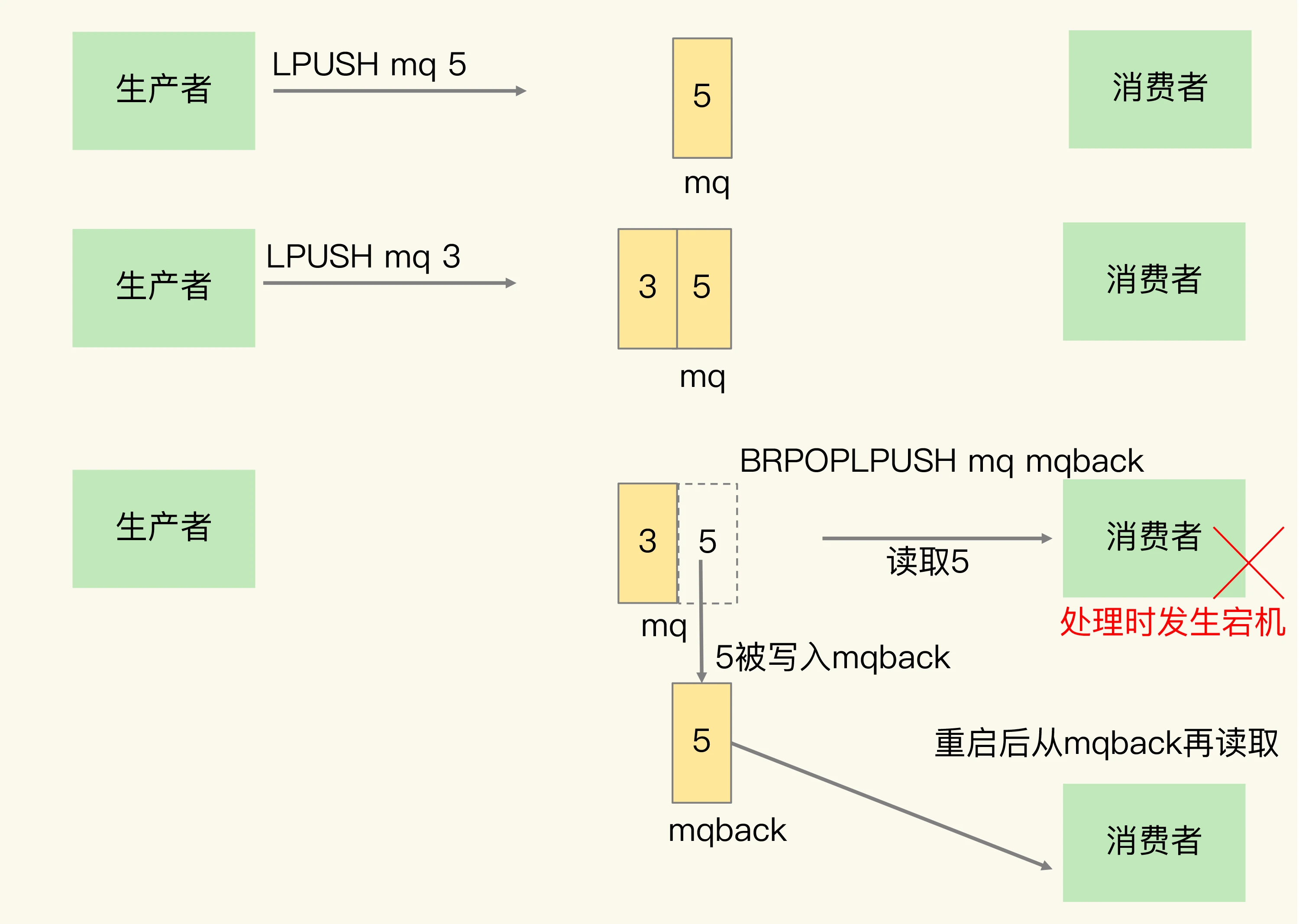
- 存在的问题
当生产者消息生产能力远远大于消费者的消费能力时,会导致List中的数据堆积,增大Redis内存压力,此时可以启动多个消费者程序组成消费组共同分担消费压力,但List类型并不支持消费组的实现,需要使用Redis5.0版本开始提供的Streams类型
基于Streams的消息队列解决方案
Streams是Redis专门为消息队列设计的数据类型,提供了丰富的消息队列操作命令XADD: 插入消息,保证有序,自动生成全局唯一IDXREAD: 读取消息,可以根据 ID 读取数据,可以设置block配置项,实现类似于BRPOP的阻塞读取操作XREADGROUP: 按照消费组形式读取消息XPENDING: 可以用来查询每个消费组内所有消费者已读取但未确认的消息,使用内部队列(PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用XACK确认消息处理完成XACK: 用于向消息队列确认消息处理已完成
小结
List消息队列和Streams消息队列的对比