线程池源码
一. Java 构建线程的方式
- 继承 Thread: Thread 类已经实现了 Runnable,继承 Thread 类时本质也是间接实现了 Runnable
- 实现 Runnable: Java 构建线程本质上只有 Runnable 方式
- 实现 Callable: 手动实现的话,将 Callable 的实现传入到 FutureTask,将 FutureTask 传入 Thread 的有参构造方法,FutureTask 本身也间接的实现了 Runnable 接口。
- 线程池: 线程池构建工作线程时,构建的 Worker 对象也实现了 Runnable 接口
- Lambda
二. 线程池的七个参数
- 为什么要使用线程池(多线程的目的是为了充分发挥硬件资源的性能)
- 场景: 接口优化(串行 -> 并行)
- 管理线程(控制线程数量): 线程需要占用内存资源,线程需要被 CPU 调度,如果不控制线程数量,可能造成业务处理速度变慢
- 重复利用(重复创建问题): 每次线程的构建都需要分配内存资源,使用完成后需要归还内存资源,成本很高,利用连接池的思想构建好反复用
- JDK 提供了 Executors 的工具类,方便构建常用的线程池,由于 Executors 封装好之后,很多参数无法主动设置,无法更好管理线程池,使用线程池时强烈推荐手动构建 ThreadPoolExecutor
七个参数

- corePoolSize: 核心线程数,核心线程默认情况下不会被销毁,一直留在线程池中
- maximumPoolSize: 最大线程数,核心线程数 + 非核心线程数
- keepAliveTime: 非核心线程的最大空闲时间
- TimeUnit: 最大空闲时间单位
- BlockingQueue: 阻塞队列,有任务时先让核心线程处理,核心线程处理不过来时,堆放在 BlockingQueue 中,实在无法处理时,临时构建非核心线程处理 workQueue 中的任务
- threadFactory: 构建 thread 对象的工厂
- RejectedExecutionHandler: 拒绝策略,所有线程没有空闲,并且阻塞队列放满时,对新任务的拒绝策略
三. 线程池属性标识 & 线程池的状态
3.1 核心属性
线程池中的核心属性是 int 类型的 ctl,ctl 的高 3 位维护了线程池状态,低 29 位维护了工作线程个数
//线程池的核心属性 ctl
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// ctl 属性标识了线程池的两个信息
// int 是一个 32 个 bit 位的数值,其中高 3 位表示线程池状态,低 29 位表示工作线程个数(工作线程的最大值:2^29-1)
// Integer.SIZE 是获取 int 类型占用的位数,Integer.SIZE = 32
private static final int COUNT_BITS = Integer.Size - 3
// CAPACITY 表示线程池中最大的工作线程个数
private static final int CAPACITY = (1 << COUNT_BITS) - 1
// 00000000 00000000 00000000 00000001 (1)
// 00100000 00000000 00000000 00000000 (1 << 29)
// 00011111 11111111 11111111 11111111 (1 << 29) - 1
线程池的状态
- RUNNING: 一切正常,任务正常处理
SHUTDOWN: 不接收新任务,但是正在处理的任务要完成,阻塞队列的任务要处理完毕
STOP: 不接收新任务,中断正在处理的任务,阻塞队列的任务全部丢掉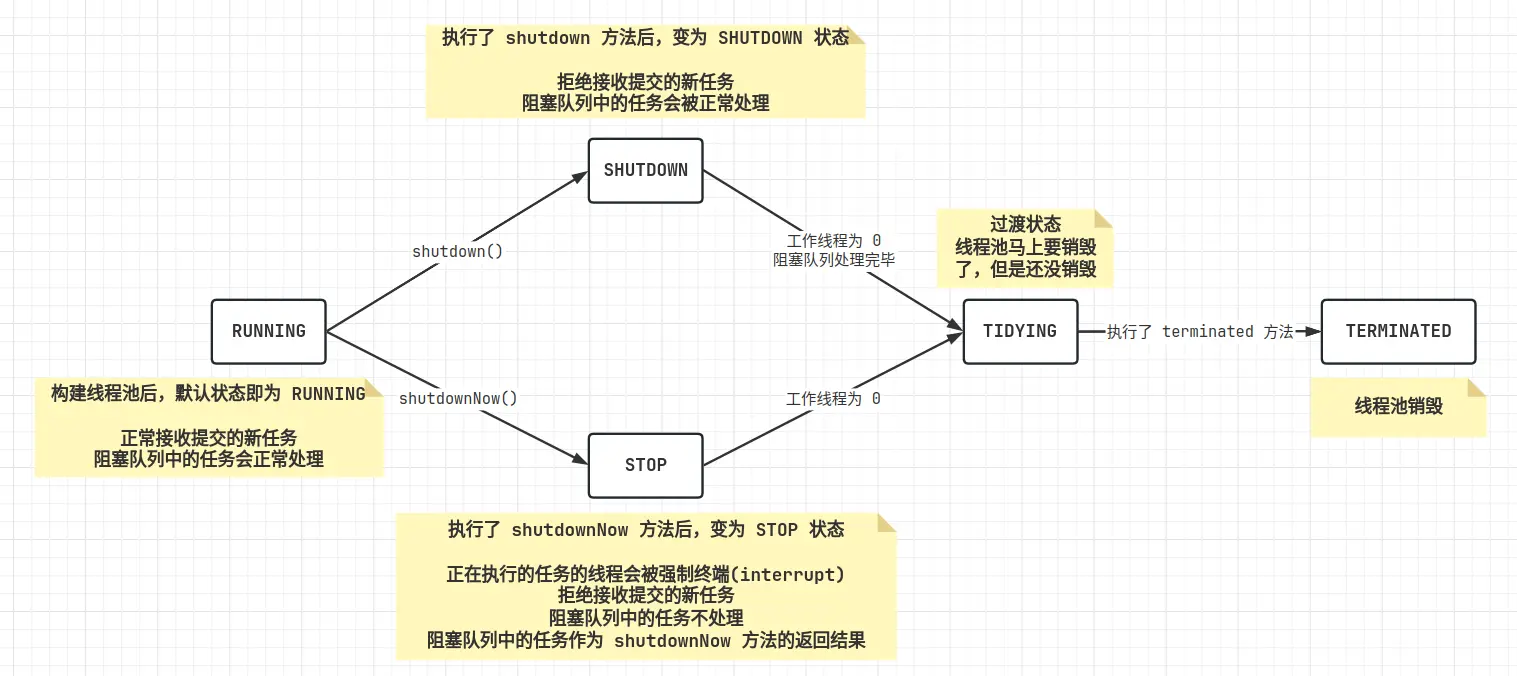
// 线程池的 5 个状态
private static final int RUNNING = -1 << COUNT_BITS; // 111
private static final int SHUTDOWN = 0 << COUNT_BITS; // 000
private static final int STOP = 1 << COUNT_BITS; // 001
private static final int TIDYING = 2 << COUNT_BITS; // 010
private static final int TERMINATED = 3 << COUNT_BITS; // 011
四. 线程池的执行流程
- 分析执行流程需要查看 execute 方法
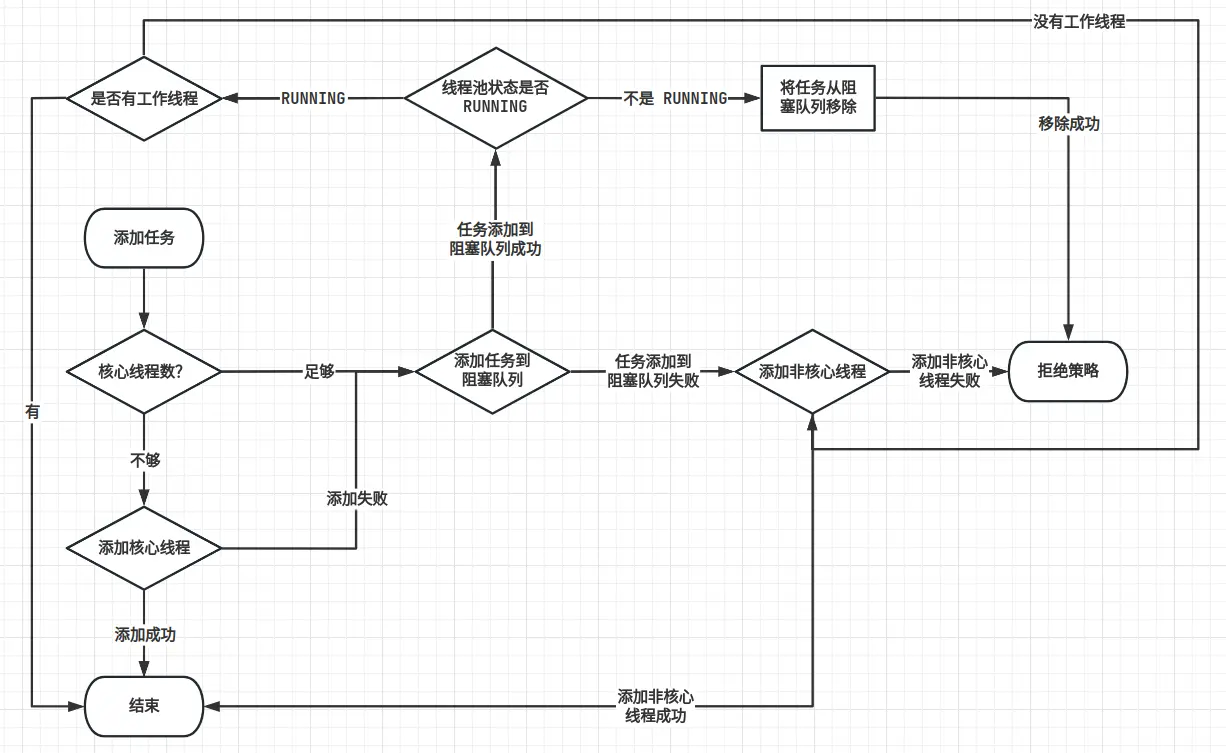
// 提交任务到线程池的方法
public void execute(Runnable command){
// 非空判断
if (command = null)
throw new NullPointerException();
// 获取核心属性
int c = ctl.get();
// workerCountOf: 获取工作线程个数
// 当前工作线程个数 < 核心线程数
if (workerCountOf(c) < corePoolSize ) {
// 添加 1 个工作线程
// true: 核心线程 false: 非核心线程
// 添加工作线程会有并发问题,添加成功返回true,添加失败返回false
if (addWorker(command, true))
// 如果添加成功,返回
return;
// 添加失败,重新获取 ctl,判断情况
c = ctl.get();
}
// inRunning: 线程池状态是否为 RUNNING
// 如果是 RUNNING,就把任务扔到阻塞队列中排队
if (inRunning(c) && workQueue.offer(command)){
// 再次获取 ctl 属性
int recheck = ctl.get();
// 再次确认线程池状态是否 RUNNING,如果不是 RUNNING,把任务从阻塞队列移除
if (!isRunning(recheck) && remove(command))
// 执行拒绝策略
reject(command);
// 阻塞队列中有任务但是没有工作线程
else if (workerCountOf(recheck) == 0)
// 创建一个非核心线程去处理阻塞队列中的任务
addWorker(null, false);
}
// 如果任务添加到阻塞队列失败,添加非核心线程处理任务
else if (!addWorker(command, false))
// 如果添加非核心线程失败,执行拒绝策略
reject(command);
}
五. 添加工作线程的流程
添加工作线程本质就是 addWorker 的流程
private boolean addWorker(Runnable firstTask, boolean core) {
// ==================线程池状态 & 工作线程个数判断==================
retry: // 标识,用于在内层 for 循环退出外层 for 循环
for (;;) {
// 拿到 ctl 并拿到高三位的值
int c = ctl.get();
int rs = runStateOf(c); // 线程池状态
// 状态 >= SHUTDOWN (如果状态不是 RUNNING,不需要添加工作线程)
if (rs >= SHUTDOWN &&
// 阻塞队列有任务,没有工作线程,会 addWorker(null, false);
// 线程池状态时 SHUTDOWN,并且阻塞队列有任务,没有工作线程可以处理
// 针对 addWorker(null, false) 的放行
! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))
// 走到这一步就无法处理,线程池状态不对,直接退出
return false;
// 判断工作线程个数
for (;;) {
int wc = workerCountOf(c); // 获取工作线程个数
if (wc >= CAPACITY || // 如果大于 低29位,直接退出
wc >= (core ? corePoolSize : maximumPoolSize)) // 根据core 决定线程数判断依据(核心线程数/最大线程数)
return false; // 超过直接返回false
if (compareAndIncrementWorkerCount(c)) // 基于 CAS 对 clt + 1
break retry; // 如果成功,直接跳出外层循环
// 没有跳出循环说明 CAS 失败,出现并发情况,重新获取 ctl
c = ctl.get();
if (runStateOf(c) != rs) // 如果状态改变了,重新进行外层 for 循环
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// ==================创建工作线程 & 启动工作线程==================
boolean workerStarted = false; // 任务是否成功启动标识
boolean workerAdded = false; // 任务是否添加成功标识
Worker w = null;
try {
w = new Worker(firstTask); // new 一个工作线程,将任务扔进去
final Thread t = w.thread; // 拿到工作线程的 Thread
// Thread 是 ThreadFactory 构建出来的,如果构建的是 null,表示程序员提供的 ThreadFactory 有问题
if (t != null) {
// 加锁,因为后面会对 HashSet 以及 int 进行操作,保证线程安全
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
int rs = runStateOf(c);
// 状态是否 RUNNING
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // 线程是否启动,避免程序员提供的 ThreadFactory 有问题
throw new IllegalThreadStateException();
workers.add(w); // 工作线程添加到 Set 集合,用 HashSet 维护工作线程
int s = workers.size();
// largestPoolSize 记录线程池中工作线程的最大值
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; // 添加成功标识
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 添加工作线程成功,启动工作线程,并且设置 workerStarted 为 True
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
六. Worker 的封装 & 后续任务的处理
调用 Worker 的有参构造方法时,会基于 ThreadFactory 构建线程,并且将 Worker 对象本身作为 Runnable 传入到 Thread 对象中,当执行 Thread 的 start 方法时,会执行 Worker 的 run 方法,最终执行的是 run 方法内部的 runWorker 方法
final void runWorker(Worker w){
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock()
boolean completedAbruptly = true;
try {
// 任务的处理方式有 2 种
// 1. 直接基于 addWorker 携带过来的任务,优先处理
// 2. 如果 addWorker 携带的任务处理完毕或者没携带任务,直接从阻塞队列中获取
while(task != null || (task = getTask()) != null){
// 处理任务!!!省略
task.run();
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
// 省略部分代码
private Runnable getTask() {
for(;;) {
try {
Runnable r = timed ?
// 从阻塞队列获取任务
// 如果执行 poll,代表非核心线程,等待一会,没任务则退出(有最大空闲时间)
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
// 如果执行 take,代表是核心线程,死等
workQueue.take();
if (r != null)
return r;
} catch (InterruptedException retry) {
timeOut = false;
}
}
}