MySQL 索引原理
索引的原理
索引原理
- 索引的目的在于提高查询效率
- 索引的本质是一种排好序的数据结构,通过不断缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说有了这种索引机制,我们总是可以使用同一种查找方式来锁定数据
磁盘 IO 与预读
- 因为磁盘 IO 是非常高昂的操作,操作系统做了一些优化,当一次 IO 时,不光把当前磁盘地址的数据,同时也将相邻的数据都读取到内存缓冲区中
因为局部预读性原理告诉我们,当计算机访问一个地址的数据时,其相邻的数据也会很快被访问到,每一次 IO 读取的数据我们称之为一页(page)
具体一页有多大数据跟操作系统有关,一般为 4k 或 8k,也就是我们读取一页内的数据时,实际上只发生了一次 IO,这个理论对于索引的数据结构设计非常有帮助
索引的数据结构
- 索引的数据结构要求:每次查找数据时都把磁盘 IO 次数控制在一个很小的数量级(最好是常数数量级),因此需要一个高度可控的多路搜索树(B+ 树)
- B+ 树的定义

磁盘块:浅蓝色,每个磁盘块包含几个数据项(深蓝色)和指针(黄色)
真实数据存在于叶子节点,即 3、5、9、10、13、15、28、29、36、60、75、79、90、99
非叶子节点不存储真实数据,之存储指引搜索方向的数据项,比如 17、35 并不真实存在于数据表中 - B+ 树的查找过程
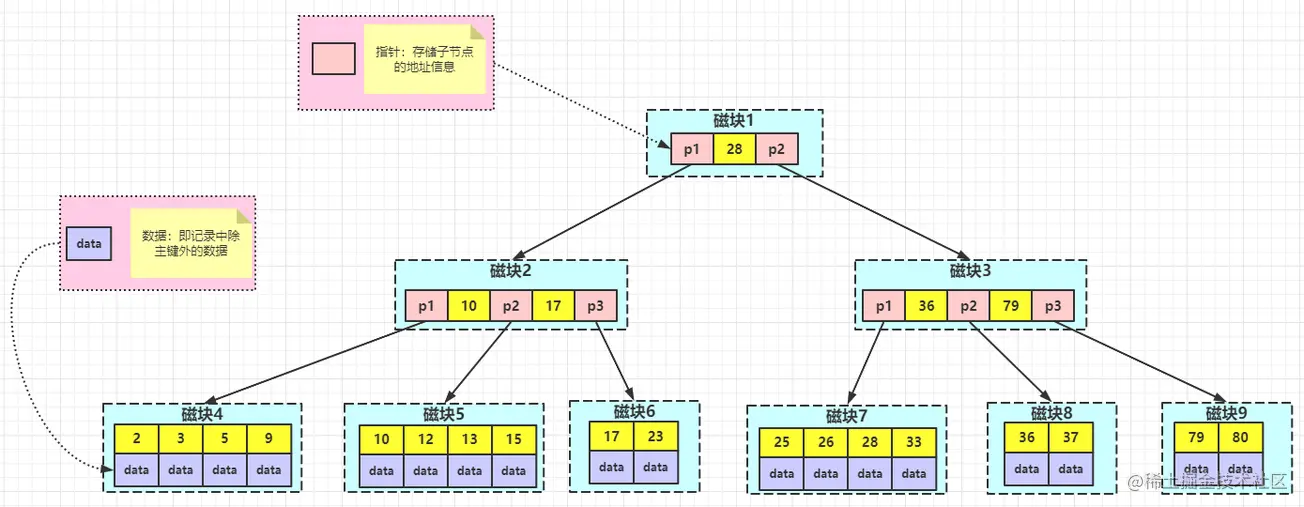
加入查找图中数据项 29,首先会把磁盘块 1 从磁盘加载到内存,此时发生一次 IO,在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间相比磁盘 IO 可以忽略不计,通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 从磁盘加载到内存,发生第二次 IO,29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指针,加载磁盘块 8,发生第三次 IO,在内存中做二分查找找到 29,结束查询,总计三次 IO
真实情况中,三层的 B+ 树可以表示上百万的数据,如果上百万的数据查找只需要三次 IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次 IO,总共需要百万次 IO,成本显然极高 - B+ 树的性质
- 索引字段尽量小:IO 次数取决于 B+ 树的高度 h ,假设当前数据表的数据为 N,每个磁盘块上的数据项的数量是 m,则
h = log(m+1)N,当数据量 N 一定的情况下,m 越大,h 越小,而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量就越多,树的高度越低。 因此要求每个数据项(即索引字段)尽量的小,这也是 B+ 树要求把真实数据放到叶子节点而不是内层节点的原因,一旦放到内层节点,磁盘块的数据项数量会大幅下降,导致树增高,当数据项等于 1 时会退化成线性表 - 索引的最左匹配特性(从左往右匹配)
当 B+ 树的数据项是复合的数据结构时(比如:(name,age,sex)),B+ 树是按照从左到右的顺序来创建搜索树的,比如当(张三,20,F)这样的数据来检索的时候,B+ 树会优先比较 name 来确定下一步的搜索方向,如果 name 相同再依次比较 age 和 sex,最后得到检索的数据。 但当 (20,F) 这样的没有 name 的数据来检索的时候,B+ 树就不知道下一步该查哪个节点,因为建立搜索树时 name 就是第一个比较因子,必须要先根据 name 来搜索才能知道下一步的查询方向
当 (张三,F) 这样的数据进行检索的时,B+ 树可以先用 name 来指定搜索方向,但下一个字段 age 缺失,因此只能把name="张三"的数据都找到,然后再匹配性别是 F 的数据
- 索引字段尽量小:IO 次数取决于 B+ 树的高度 h ,假设当前数据表的数据为 N,每个磁盘块上的数据项的数量是 m,则
MySQL 索引管理
功能
- 索引的功能就是加速查找
- MySQL 中 primary key、unique、联合唯一 都是索引,这些索引除了加速查找之外,还有约束的功能
索引分类
- 普通索引 index:加速查找
- 唯一索引
- 主键索引:primary key,加速查找 + 约束(不为空且唯一)
- 唯一索引:unique,加速查找 + 约束(唯一)
- 联合索引
- 联合主键索引:
primary_key(id, name) - 联合唯一索引:
unique(id,name) - 联合普通索引:
index(id,name)
- 全文索引(Full-text): 用于搜索长文本的时候效果最好
- 空间索引(spatial):基本不会使用
索引的两大类型 hash 和 btree
- 创建索引时可以指定索引类型,分为两类
- hash 索引:查询单条快,范围查询慢
- btree 索引:B+ 树,层数越多,数据量指数级增长(InnoDB 默认使用)
- 不同存储引擎支持的索引类型
- InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引
- MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引
- Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引
- NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引
- Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引
B+ 树的演化
- 二叉排序树
对于一个节点,它的左子树的孩子节点的值都要小于它本身,右子树的孩子节点值都要大于它本身,所有节点满足这个条件,就是一颗二叉排序树
在二叉排序中,查找元素 9,查找成功一共比较了 4 次
在极端情况下二叉树会出现链化的情况,即节点一直在某一边增加 - AVL(自平衡二叉查找树)

上图的 AVL 树节点个数和值均和二叉排序树一模一样
查找元素 9 时,查找成功一共比较了 3 次
原因是 AVL 树的高度比二叉排序树小,高度越高意味着比较次数越多,海量数据时比较次数会明显增长 - B 树(Balanced Tree,多路平衡查找树)
AVL 树需要比较 3 次,采用降低树高的思想继续优化,每个节点存放多个值,可以显著降低树的高度
假设每个节点存储两个值
查找元素 9 时,查找成功一共比较了 2 次B 树的缺点:B 树的每个节点中不仅包含数据的 key 值,还有 data 值
然而每页的存储空间都是有限的,如果 data 值较大,会导致每个节点的 key 存储较少,当数据量较大的时候,同样会导致 B 树很深,从而增加磁盘 IO 的次数,进而影响查询效率 - B+ 树
B+ 树的非叶子节点不直接存储可以从磁盘中取出关键值的指针,而是存储关键值的索引,关键值只存储在叶子节点中,并且叶子节点组成一个有序链表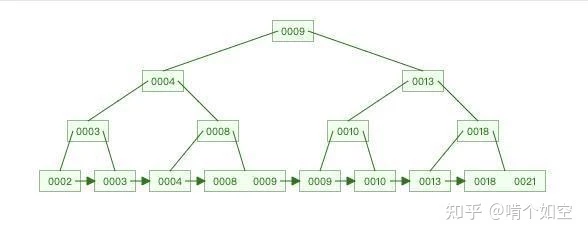
B+ 树的优点:比较次数均衡,减少了 IO 次数,提高查找速度,查找更加稳定,磁盘读写代价更低,查询效率更加稳定
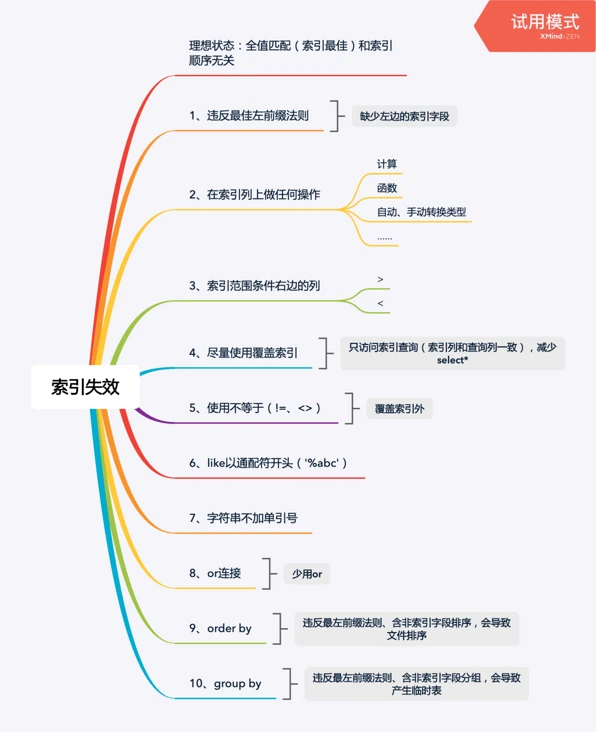
索引失效情况
部分关键概念
回表
数据库中创建了 name、age 索引 ng_index,查询数据时使用select * from table where name ='bill' and age = 21;由于附加索引中只有 name 和 age,因此命中索引后,数据库还需要回去聚集索引中查找其他数据,这就是回表,同时也是尽可能减少使用
select *的原因索引覆盖
比如上述 ng_index 索引,查询语句select name, age from table where name ='bill' and age = 21;此时 select 的字段 name、age 在索引 ng_index 中都能获取到,不需要回表,满足索引覆盖,效率较高
最左匹配
B+ 树的节点存储索引顺序是从左向右存储,因此匹配的时候也要满足从左向右匹配
比如索引 ng_index,下列的 SQL 都可以命中这个索引select name from table where name = 'bill';select name, age from table where name = 'bill' and age = 18;索引下推
上述索引 ng_index,有如下 SQLselect * from table where name like 'B%' and age > 20该 SQL 有两种执行可能
- 命中 ng_index 联合索引,查找所有满足 name 以 B 开头的数据,然后回表查询所有满足行的数据
- 命中 ng_index 联合索引,查找所有满足 name 以 B 开头的数据,然后直接筛出
age > 20的索引,再回表查询全行数据
第 2 种方式回表查询次数较少,IO 次数相应减少,这种情况就是索引下推