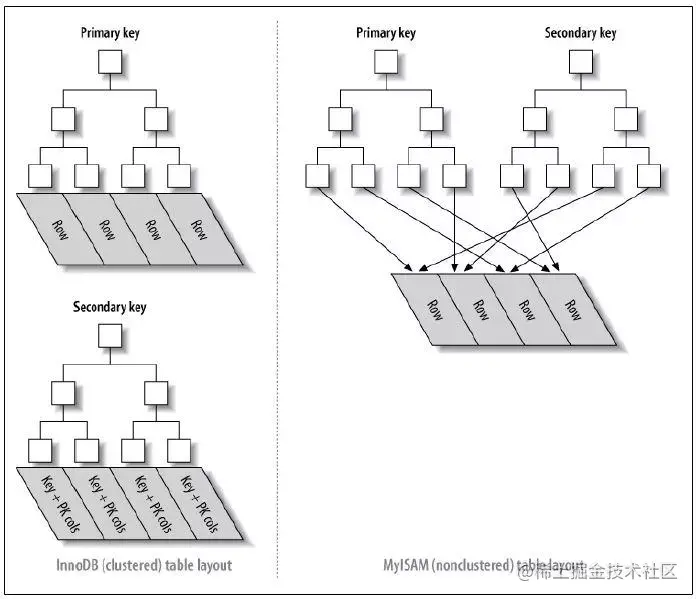
聚簇索引和非聚簇索引
InnoDB 的次索引指向对主键的引用(聚簇索引)
MyISAM 的次索引的主索引都指向物理行(非聚簇索引,也叫二级索引)聚簇索引:对磁盘上实际数据重新组织以指定的一个或多个列的值排序的算法
特点:存储数据的顺序和索引顺序一致,一般情况下主键或默认创建聚簇索引,且一张表只允许存在一个聚簇索引(因为数据一旦存储,顺序只能有一种)聚簇索引和非聚簇索引的区别
叶子节点是否存放一整行记录
InnoDB 主键使用聚簇索引,MyISAM 不管是主键索引还是二级索引都使用非聚簇索引
- 非聚簇索引
表数据和索引分成两部分进行存储,主键索引和二级索引存储上没有任何区别,使用 B+ 树作为索引的存储结构,所有的节点都是索引,叶子节点存储的是索引 + 索引对应记录的数据 - 聚簇索引
表数据和主键一起存储,主键索引的叶子节点存储行数据(包括主键值),二级索引的叶子节点存储行的主键值
使用 B+ 树作为索引的存储结构,非叶子节点都是索引关键字,但非叶子节点中的关键字中不存储对应记录的具体内容或内容地址,叶子节点上的数据是主键和具体记录(数据内容)- 优点
- 需要取出一定范围内的数据时,聚簇索引优于非聚簇索引
- 通过聚簇索引查找目标数据是理论上比非聚簇索引快,因为非聚簇索引定位到对应主键还要多一次目标记录寻址,即多一次 I/O
- 使用覆盖索引扫描的查询可以直接使用叶子节点中的主键值
- 缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则会出现页分裂,严重影响性能,因此对于 InnoDB 表,一般都会定义一个自增的 ID 列为主键
- 更新主键的代价高,因为会导致被更新的行移动,因此对于 InnoDB 表一般定义主键为不可更新
- 二级索引访问需要两次索引查找,第一次查找主键值,第二次查找根据主键值查找行数据
二级索引的叶子节点存储的是主键值而不是行指针(非聚簇索引存储的是指针或者是地址),这是为了减少行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多空间 - 插入新值时,采用聚簇索引比采用非聚簇索引速度慢很多,因为要保证主键不能重复,采用的方式在不同的索引下会有很大的性能差距,聚簇索引和非聚簇索引都需要遍历所有的叶子节点,但是聚簇索引的叶子节点同时带有主键和记录值,记录的大小往往比主键要大得多,因此会导致聚簇索引在判定新记录携带的主键是否重复时 I/O 代价更高
- 优点
- 非聚簇索引
InnoDB 在进行数据插入的时候必须要绑定到一个索引列上,默认是主键,没有主键时会选择唯一键,两者都没有时会生成 6 字节的 ROWID,跟数据绑定在一起的我们称为聚簇索引,没有跟数据绑定在一起的索引称为非聚簇索引 InnoDB 引擎既有聚簇索引也有非聚簇索引,而 MyISAM 只有非聚簇索引