ForkJoin框架
- Fork/Join 框架是 Java 并发工具包中一种可以将一个大任务拆分为多个小任务来异步执行的工具,自 JDK1.7 引入
框架简介
三个模块
- 任务对象: ForkJoinTask(包括 RecursiveTask、RecursiveAction、CountedCompleter)
- 执行 Fork/Join 任务的线程:ForkJoinWorkerThread
- 线程池:ForkJoinPool
- 三者的关系
ForkJoinPool 可以通过池中的 ForkJoinWorkerThread 来处理 ForkJoinTask 任务
ForkJoinPool 只接受 ForkJoinTask 任务(实际使用中也可以接受 Runnable/Callable 任务,但真正运行时也会把这些任务封装成 ForkJoinTask 类型的任务)
实际使用中一般不会直接继承 ForkJoinTask 类,而是继承以下三个类- RecursiveTask:是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask
- RecursiveAction:是一个无返回值的 RecursiveTask
- CountedCompleter:在任务完成执行后会触发执行一个自定义的钩子函数
核心思想
- 分治算法(Divide-and-Conquer)
把任务递归的拆分为各个子任务,可以更好的利用系统资源,尽可能使用所有可用的计算能力来提高应用性能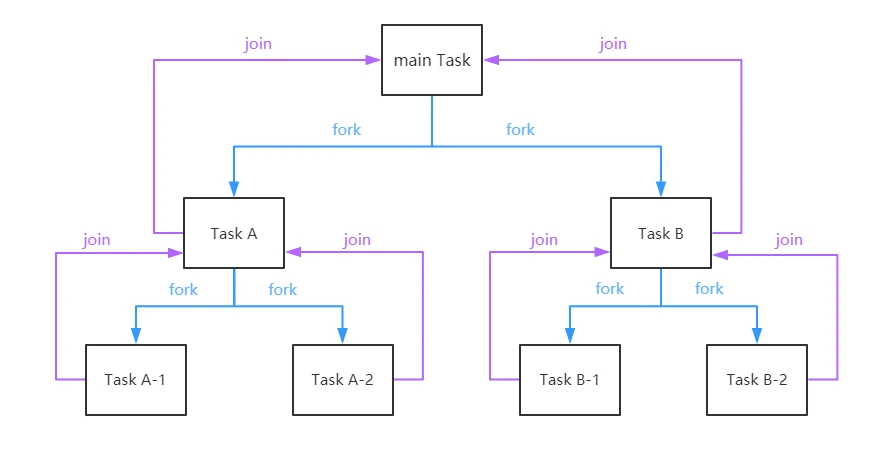
- 工作窃取算法(work-stealing)
线程池内所有的工作线程都尝试找到并执行已经提交的任务,或者是被其他任务创建的子任务(如果不存在则阻塞等待)
这种特性使 ForkJoinPool 在运行多个可以产生子任务的任务、或者提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(Join)的事件类型任务也非常适用
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO/FIFO顺序,由参数 mode 决定),然后以 FIFO 的顺序随机窃取其他队列中的任务- 具体思路
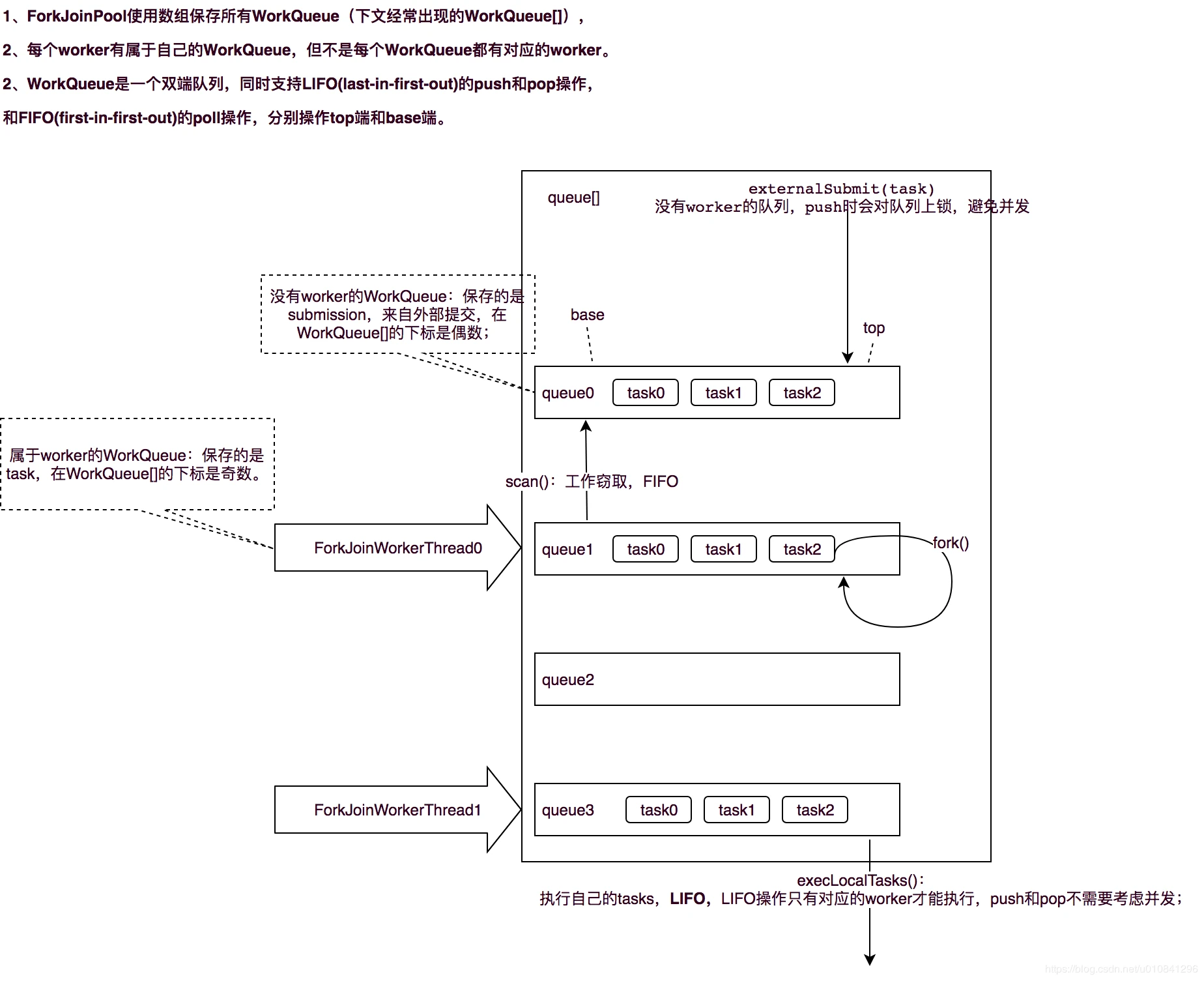
- 每个线程都有自己的一个 WorkQueue,该工作队列是一个双端队列
- 队列支持三个功能:push、pop、poll
- push/pop 只能被队列的所有者线程调用,而 poll 可以被其他线程调用
- 划分的子任务调用 fork 时,都会被 push 到自己的队列中
- 默认情况下,工作线程从自己的双端队列获取任务并执行
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用 poll 方法窃取任务
- 获取自身任务时从尾部获取,获取其他线程任务时从头部获取

- 具体思路
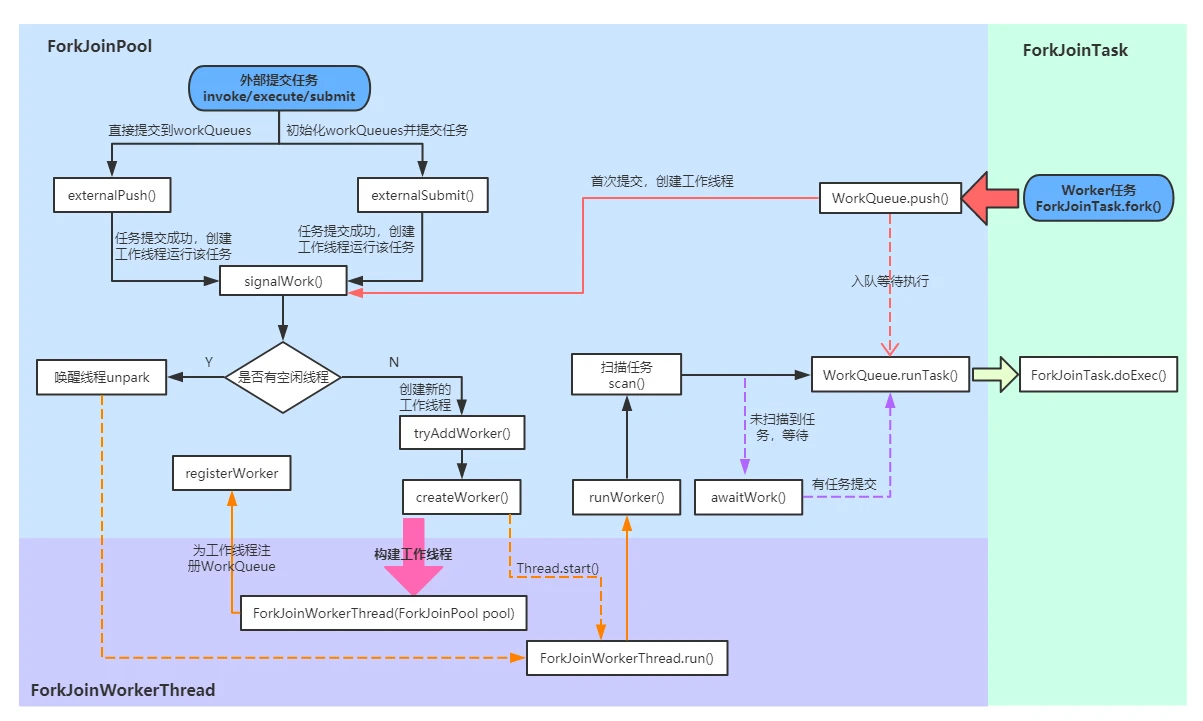
执行流程
- ForkJoinPool 中的任务执行分为两种
- 直接通过 FJP 提交的外部任务(external/submission task),存放在 workQueue 的偶数槽位
- 通过内部 fork 分割的子任务(Worker task),存放在 workQueue 的奇数槽位
- 执行流程
源码
陷阱和注意事项
避免不必要的 fork
- 划分成两个子任务后,不要同时调用两个子任务的 fork 方法
表面上两个子任务都 fork,然后 join() 两次似乎更加自然,事实上直接调用 compute() 方法效率更高,因为直接调用 compute() 方法等于在当前的工作线程进行了计算(线程重用),这比将子任务提交到工作队列,线程又从工作队列中拿任务快得多 - 当一个大任务被划分成两个以上的子任务时,尽可能使用前面提到的三个 invokeAll 方法,能尽量避免不必要的 fork
fork()、compute()、join() 的顺序
- 为了两个任务并行,要注意三个方法的调用顺序 其他顺序都可能会导致没有并行
right.fork(); // 计算右边的任务
long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)
long rightAns = right.join(); // 等待右边的结果
return leftAns + rightAns;
选择合适的子任务粒度
- 选择划分子任务的粒度(顺序执行的阈值)很重要,因为 Fork/Join 框架并不一定比顺序执行任务效率高:任务太大则无法提高并行吞吐量,任务太小则子任务的调度开销可能大于并行计算的性能提升,同时还要考虑创建子任务、fork() 子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗
避免重量级任务划分和结果合并
- Fork/Join 很多使用场景都用到数组或者 List 等数据结构,子任务在某个分区中运行,最典型的例子:并行排序、并行查找。拆分子任务以及合并处理结果时,应尽量避免 System.arraycopy 这类耗时耗空间的操作,从而最小化任务的处理开销
深入理解
使用 Fork/Join 思想的 JDK 源码
- 常用数组工具类 Arrays 在 JDK8 之后新增的并行排序方法(parallelSort)使用了 ForkJoinPool 的特性
- ConcurrentHashMap 在 JDK8 后添加的函数式方法(forEach 等)也有运行
使用 Executors 工具类创建 ForkJoinPool
- Java8 在 Executors 工具类中新增了两个工厂方法
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
异常处理
ForkJoinTask 内部把受检异常转换成了运行时异常
static void rethrow(Throwable ex) {
if (ex != null)
ForkJoinTask.<RuntimeException>uncheckedThrow(ex);
}
@SuppressWarnings("unchecked")
static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {
throw (T)t; // rely on vacuous cast
}ForkJoinTask 提供两个不提取结果和异常的方法 quietlyInvoke()、quietlyJoin(),这两个方法允许你在所有任务完成后对结果和异常进行处理
使用 quietlyInvoke() 和 quietlyJoin() 时可以配合 isCompletedAbnormally() 和 isCompletedNormally() 使用