JUC中的高并发集合类
ConcurrentHashMap
结构
- JDK1.7 结构
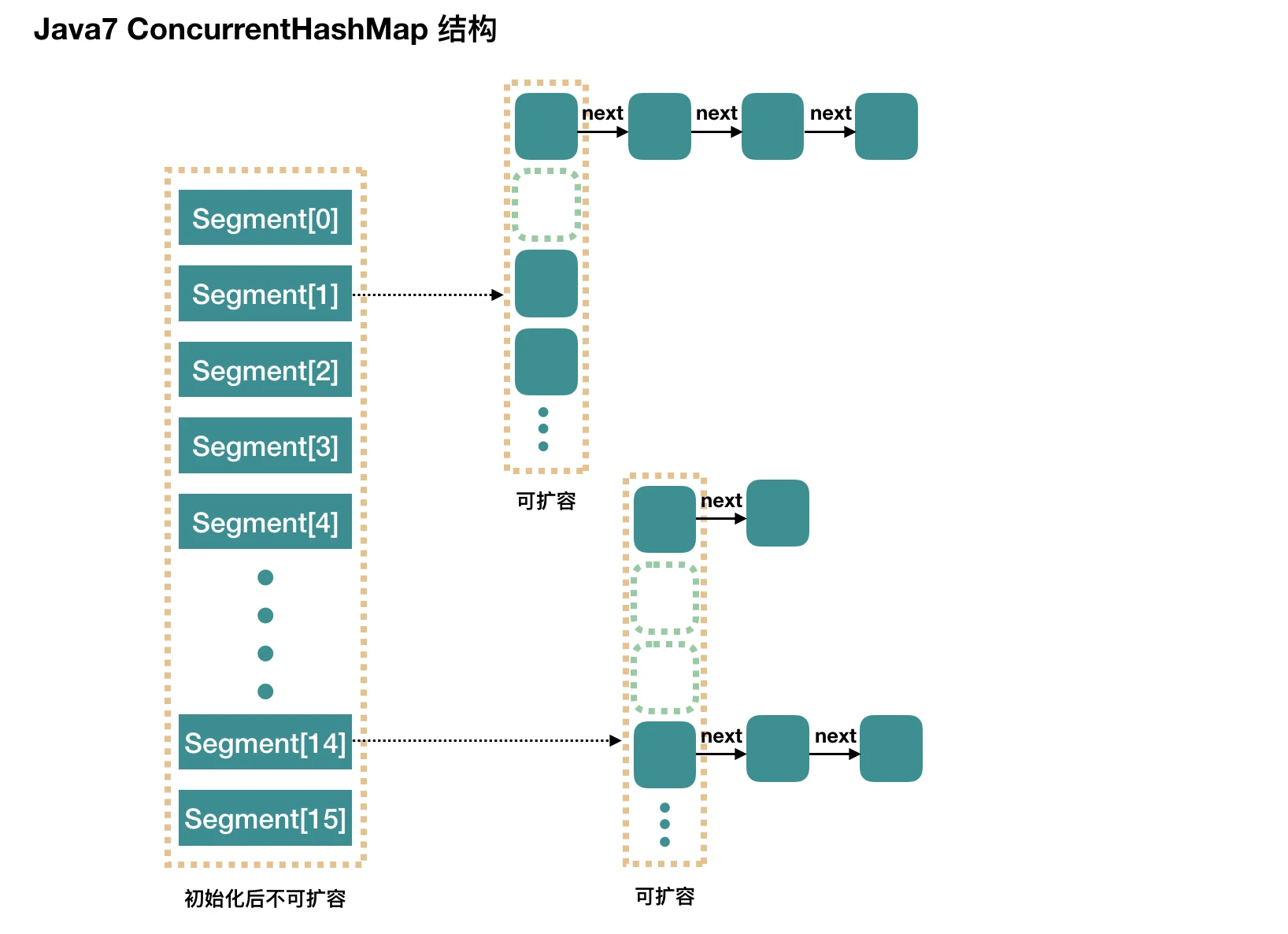
JDK1.7 中 ConcurrentHashMap 由 Segment 数据结构和 HashEntry 数组结构构成,采用分段锁保证安全性
Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap 中扮演锁的角色,HashEntry 则用于存储键值对,一个 ConcurrentHashMap 中包含一个 Segment 数组,一个 Segment 中包含一个 HashEntry,Segment 跟 HashMap 类似,是一个数组和链表结构 - JDK1.8 结构
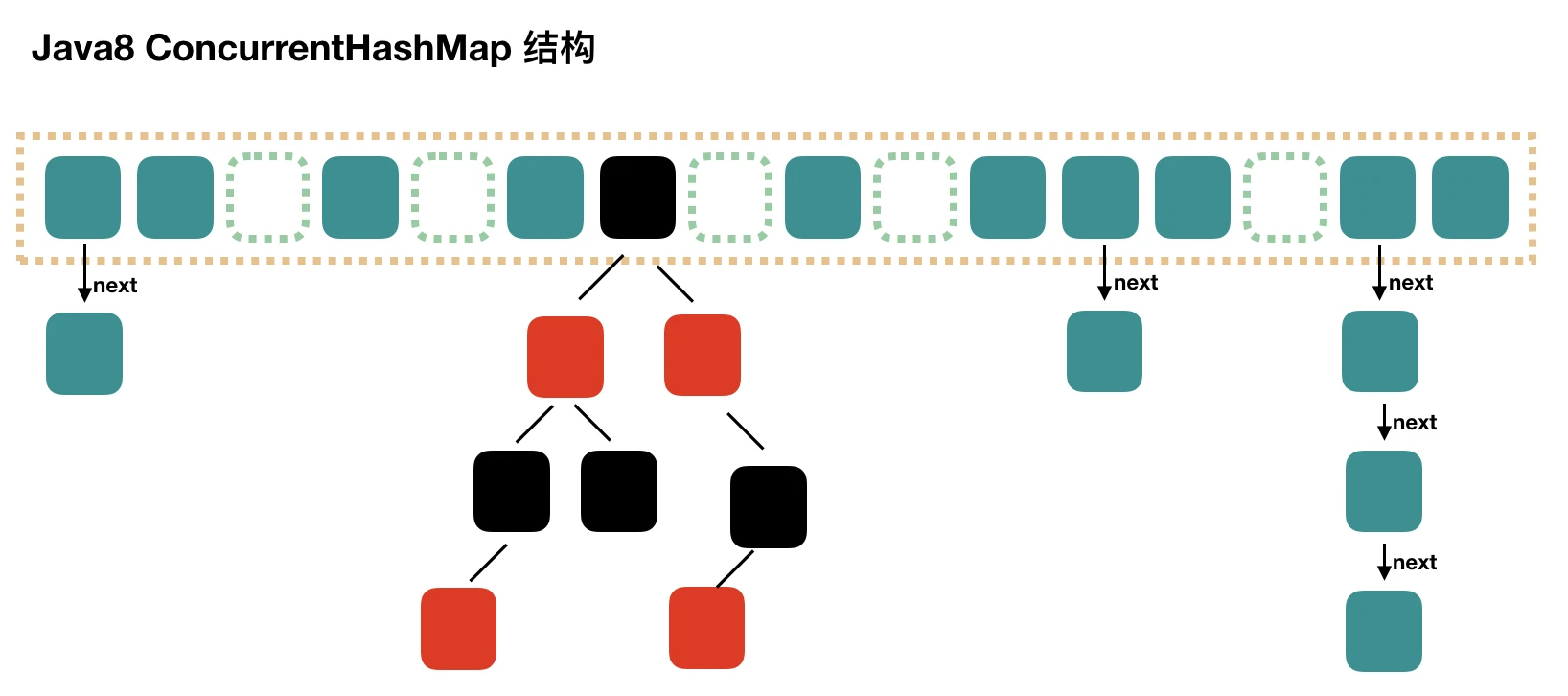
因为JDK1.7 中 ConcurrentHashMap 最大并发度受Segment的个数限制,JDK1.8 中的实现摒弃了 Segment 的概念,直接采用 Node 数组+链表+红黑树的数据结构实现,并发控制使用 Synchronized 和CAS 来操作,结构看起来就像一个优化过且线程安全的 HashMap,JDK1.8 中还能看到 Segment 的数据结构,但对属性进行了简化,只是为了兼容旧版本
JDK1.8 中 Synchronized 只锁定当前链表或红黑树的首节点,只要 hash 不冲突,就不会产生并发(效率提升)
ConcurrentHashMap 和 HashTable 的区别
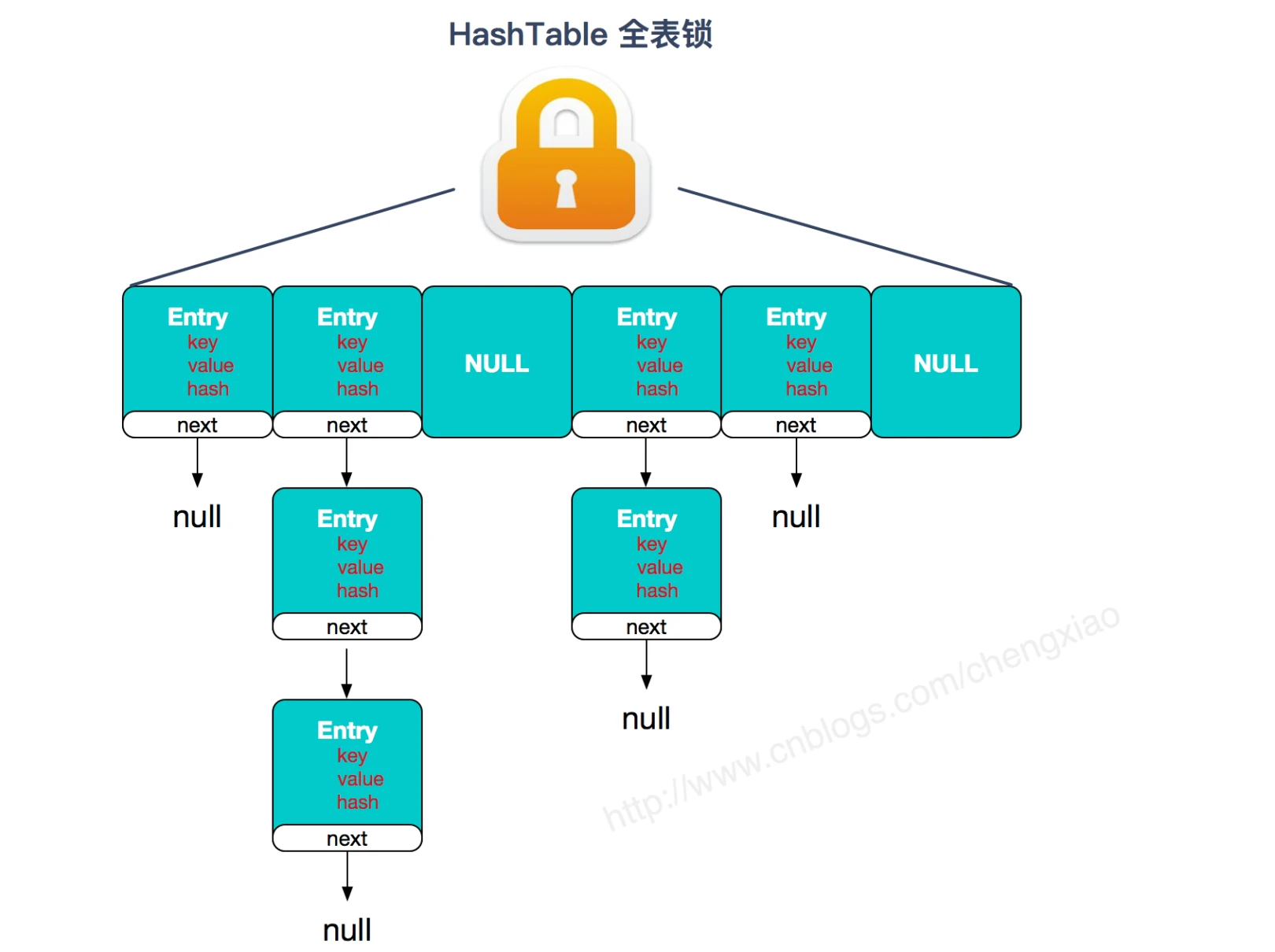
- HashTable:是一个线程安全的类,用 synchronized 来锁住整张 Hash 表来实现线程安全,即每次锁住整张表让线程独占,导致效率十分低下
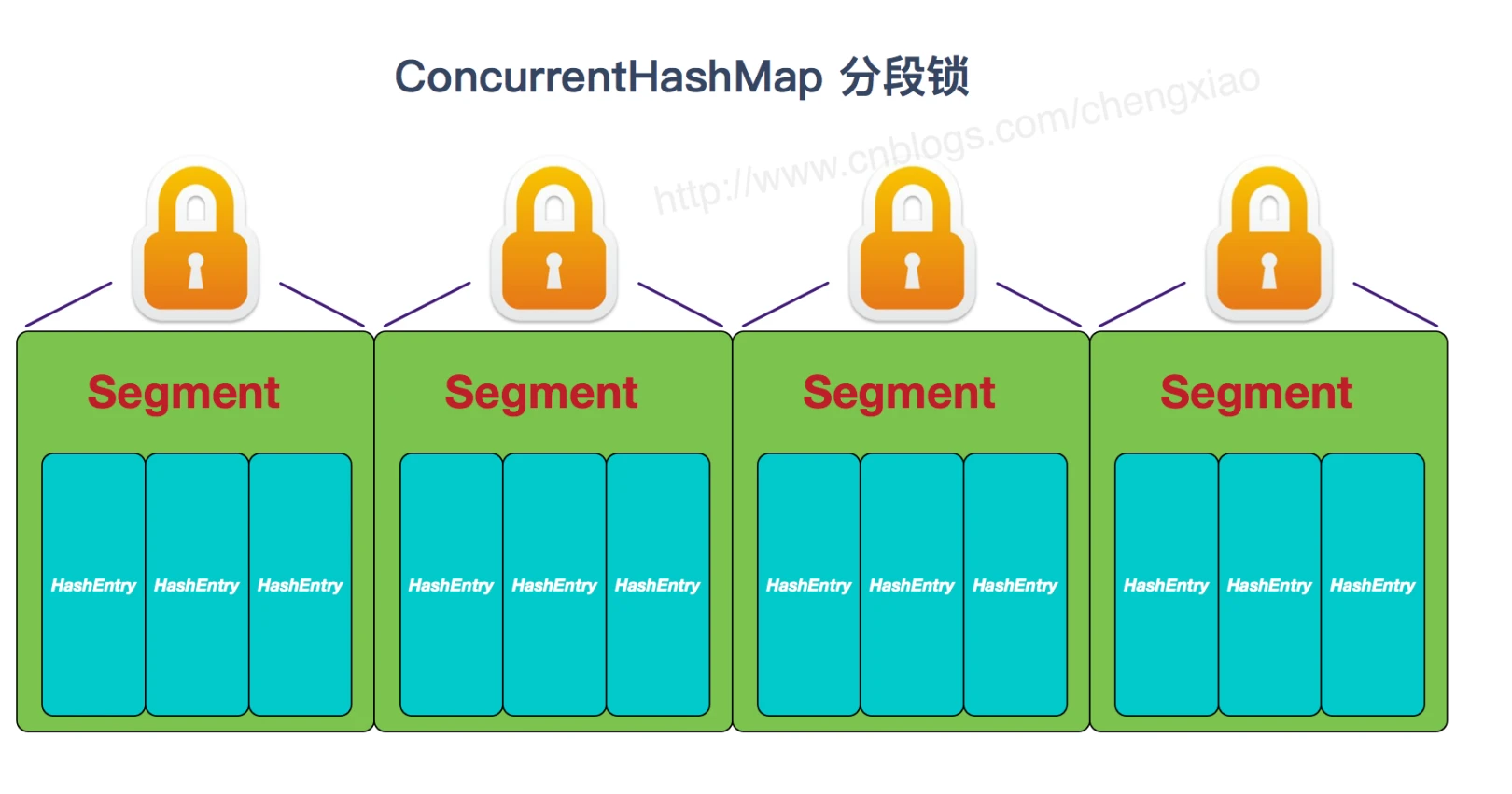
- ConcurrentHashMap:可以做到读取数据不加锁,在进行写操作的时候让锁的粒度保持尽量的小,允许多个修改操作并发进行,其关键在于使用了锁分段技术(使用了多个锁来控制对 hash 表的不同部分的修改)。
ConcurrentHashMap 内部使用段(Segment)来表示不同部分,每个段都是一个 HashTable,它们拥有自己的锁,只要多个修改操作发生在不同的段上,就可以并发进行。对于 JDK1.7 来说锁的粒度基于 Segment,包含多个 HashEntry;JDK1.8 的实现降低了锁的粒度,为 HashEntry(首节点)
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.7 实现
- get 操作:先经过一次再散列,然后使用这个散列值通过散列运算定位到 Segment,在通过散列算法定位到元素,整个过程不需要加锁,除非读到空的值才会加锁重读,原因是将使用的共享变量定义成了 volatile
- put 操作:插入过程会进行第一次 key 的 hash 定位 Segment 的位置,如果 Segment 还没有初始化,即通过 CAS 操作进行赋值,然后进行第二次 hash 操作,找到相应的 HashEntry 位置,此时利用继承过来的锁的特性,在将数据插入指定的 HashEntry 位置时,会通过继承 ReentrantLock 的 tryLock() 方法尝试获取锁,成功则插入对应位置,如果已有线程获取该 Segment 的锁,则会以自旋的方式继续调用 tryLock() 获取锁,超过指定次数则挂起,等待唤醒
- size 操作:计算 ConcurrentHashMap 的元素大小是并发操作,因为计算时有可能正在并发地插入数据,导致计算出来的值与实际不同
解决方法:先尝试2次通过不锁住 Segment 的方式统计各个 Segment 大小,统计过程中如果 count 发生变化,则采用加锁的方式进行统计
JDK1.8 实现
- 重要概念
- table:默认为 null,初始化发生在第一次插入操作,默认大小为16的数组,用来存储 Node 节点数据,扩容时大小总是2的幂次方
- nextTable:默认为 null,扩容时新生成的数组,大小为原数组的两倍
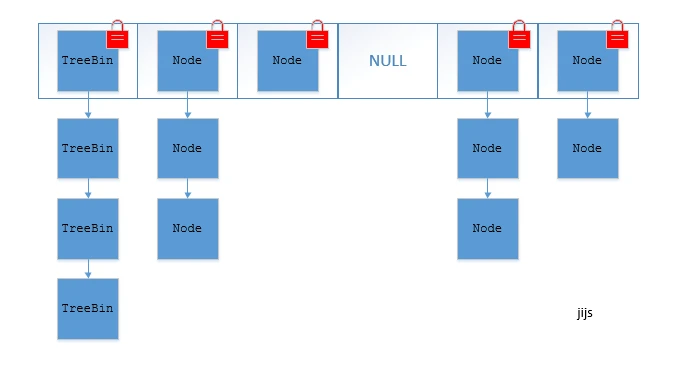
- Node:保存 key、value 以及 key 的 hash 值的数据结构,value 和 next 都用 volatile 修饰,保证并发的可见性
- ForwardingNode:一个特殊的 Node 节点,hash 值为 -1,存储了 nextTable 的引用,只有扩容时才会发挥作用,作为一个占位符放在 table 中表示当前节点为 null 或者已被移动
- TreeNode 和 TreeBin:TreeNode 表示红黑树上每个节点。与 HashMap 不同,ConcurrentHashMap 在桶里直接存储的不是 TreeNode,而是一个 TreeBin,在 TreeBin 内部维护一个红黑树
- put 操作:采用 CAS + Synchronized 实现并发插入或更新操作
对比图
- HashTable
- JDK1.7 的 ConcurrentHashMap
- JDK1.8 的 ConcurrentHashMap
CopyOnWriteArrayList
- 集合框架中 ArrayList 是非线程安全的,Vector 是线程安全的,但由于简单粗暴的锁同步机制性能较差,CopyOnWriteArrayList 则提供另外一种并发处理策略。
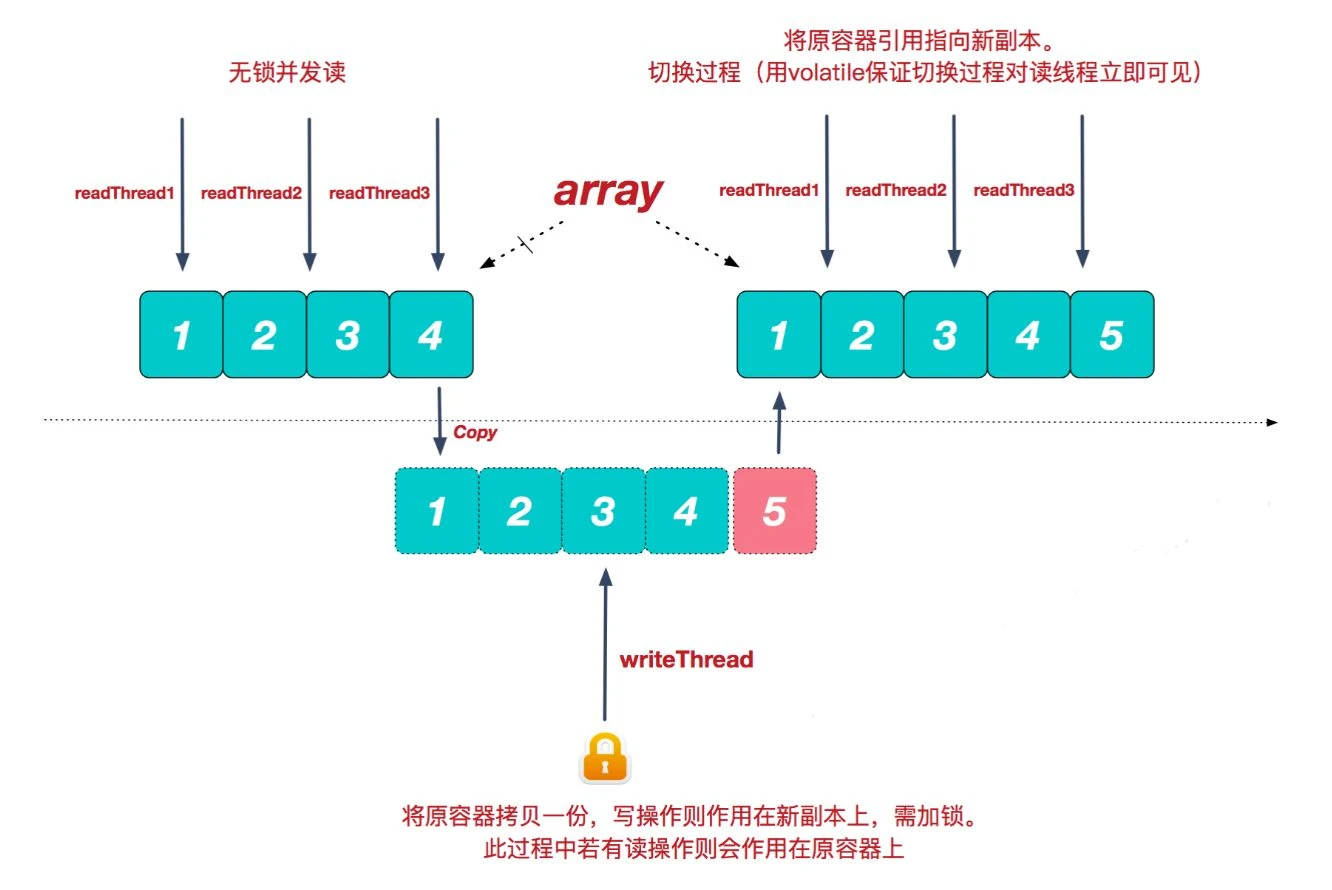
- 针对读多写少的并发场景,允许线程并发访问读操作,此时没有加锁限制,性能较高;在写操作时,则首先把容器复制一份,然后在新的副本上执行写操作,此时写操作上锁,结束后再将原容器的引用指向新容器。
- 优点是读操作性能高,无需任何同步措施,适用于读多写少的场景
缺点是需要额外内存占用,数据量大时内存压力较大,可能引起频繁 GC,而且无法保证强一致性,只能保证数据的最终一致性