锁升级
- 锁升级 = 无锁 => 偏向锁 => 轻量级锁 => 重量级锁
对象结构
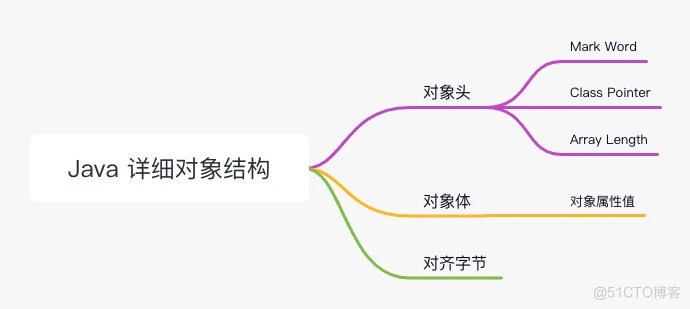
对象头
- 由 Mark Word、Class Pointer、数组长度组成
- Mark Word:主要用于存储自身运行时数据
- Class Pointer:指针,指向方法区中该 class 的对象,JVM 通过此字段来判断当前对象是哪个类的实例
- 数组长度:当且仅当对象是数组时才会有该字段
- Mark Word
Mark Word 代表的运行时数据主要用来表示当前 Java 对象的线程锁状态以及 GC 的标志。线程锁的状态分别为:无锁、偏向锁、轻量级锁、重量级锁(即 Java 内置锁的不同状态) - 线程锁的四种状态
- 无锁

单线程运行,没有其他线程与之竞争 - 偏向锁

例子:一段同步的代码,一直只被线程 A 访问,没有其他线程竞争,这种情况下线程 A 就会自动进入偏向锁的模式,后续线程 A 再次访问同步代码时就不需要进行任何 check 操作,直接执行(对该线程的偏向),以此降低获取锁的代价,提升效率
无锁、偏向锁的 lock 标志位是一样的(01),因为无锁、偏向锁靠字段 biased_lock 区分,0 代表没有使用偏向锁,1 代表启用偏向锁(无锁、偏向锁在本质上都可以理解为无锁,因此 lock 的标志位为 01)
此处线程 ID 是持有当前对象偏向锁的线程 - 轻量级锁

一旦有第二个线程参与竞争,就会立即膨胀为轻量级锁。企图抢占的线程一开始会使用自旋的方式尝试获取锁。如果循环几次后其他线程释放了锁,就不需要进行用户态到内核态的切换。但自旋锁需要占用较多 CPU 资源
JDK1.7 之前为普通自旋,自旋次数超过阈值就会停止自旋(默认 10 次),JDK1.7 后引入自适应自旋:假如此次自旋获取到了锁,自旋阈值就会增加,反之减少 - 重量级锁

试图抢占的线程自旋达到阈值后,就会停止自旋,此时锁就会膨胀成重量级锁。膨胀成重量级锁后,其他竞争的线程进来就不会自旋,而是直接阻塞等待,并且 Mark Word 中的内容会变成一个监视器对象(monitor),用来统一管理排队的线程
monitor 对象:每个对象都会关联一个,本质上是一个同步机制,保证了同时只有一个线程能够进入临界区,在 HotSpot 的虚拟机中由 C++ 类 ObjectMonitor 实现
- 无锁
对象体
包含当前对象的字段和值
对齐字节
单纯用于填充的字节,没有其他业务含义,目的是为了保证对象锁占用的内存大小为 8 的倍数
内存对齐
计算机中内存空间是按照 byte 划分的,从理论上讲似乎对任何类型变量的访问可以从任何地址开始,但实际情况是:在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定规则排列,而不是一个接一个的顺序存放,这就是对齐
内存对齐是编译器的管辖范围,具体表现为:编译器把程序中的每个数据单元安排在适当的位置上为什么要内存对齐
尽管内存以字节为单位,但大部分处理器并不按照字节读取内存,而是取决于数据类型和处理器的设置,一般以双字节、4 字节、8 字节、16 字节甚至 32 字节的块来存取内存,上述的存取单位称为内存存取粒度自然对齐:一个变量的内存地址刚好位于它本身长度的整数倍,就被称为自然对齐
例子:读取效率
假设一个整形变量(4 字节)不是自然对齐的,起始位置落在 0x00000002 (蓝色区域),处理器想要访问它的值,按照 4 字节的块进行读取,从 0x0 起读,读取 4 字节大小,读到 0x3

一次读取并不能取到想要访问的整型数据,处理器会继续再往下读,偏移 4 个字节,从 0x4 开始读到 0x7

此时处理器才能读取到我们需要访问的内存数据,这中间还存在剔除和合并的过程
因此在这个例子中,当整型变量落在 0x2 时(不补齐),处理器需要两次读取才能读取到要访问的内容

如果是对齐的,对于本例子的情况仅需读取一次便可以读取到目标数据
因此对齐与否会影响到读取效率例子:节省空间
- 单字节粒度
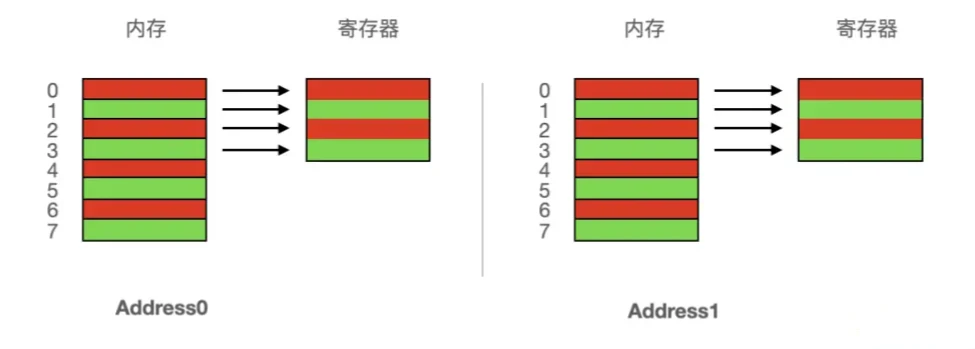
单字节存取粒度时,读取内存按照一个字节进行访问,对于每种情况都需要读取 4 次,因此内存是否对齐无影响 - 双字节粒度

从 Address0 读取 4 个字节,相比于单字节粒度,存取次数变成了一般,由于每个内存访问都需要固定的开销,因此最小化访问次数可以提高性能。同时 Address0 是内存对齐的,因此两次就可以读取到数据
从 Address1 读取时,由于该地址没有均匀的落在处理器的内存访问边界上(黑框位置为数据的内存地址区域),处理器取数据时需要先从 0 地址开始读取第一个 2 字节块01,剔除不想要的字节0,然后从地址 2 开始读取下一个 2 字节块23,再从地址 4 开始读取下一个 2字节块45,剔除不想要的字节5,读取三次后将最后留下的 3 块数据合并放入寄存器才能取到目标数据 - 四字节粒度

具有 4 字节粒度的处理器从 Address0 读取时,可以一次读取地址0123就从对齐的地址中提取四个字节
从 Address1 读取时,因为是不对齐的,读取0123,剔除0,继而读取4567,剔除地址567,读取两次后将留下的 2 块数据合并放入寄存器取到目标数据
从双字节粒度和四字节粒度可见,对于没有对齐的内存,需要做更多次的读取、剔除、合并的过程,导致效率的降低
- 单字节粒度
优点:内存对齐不仅便于 CPU 快速访问,同时合理利用字节对齐可以有效节省存储空间
对于对齐的内存,不同的存取粒度也会影响到存取效率,粒度小则存取次数多,粒度大则浪费空间,因此每个特定平台上的编译器都有自己默认的存取粒度
总结
内存对齐就是定制了一套规则以合理的利用内存空间并提高内存访问效率,编译器通过适当增加 padding,使每个成员的访问都在一个指令内完成,而不需要多次访问再拼接,是一个空间换时间的过程
锁升级
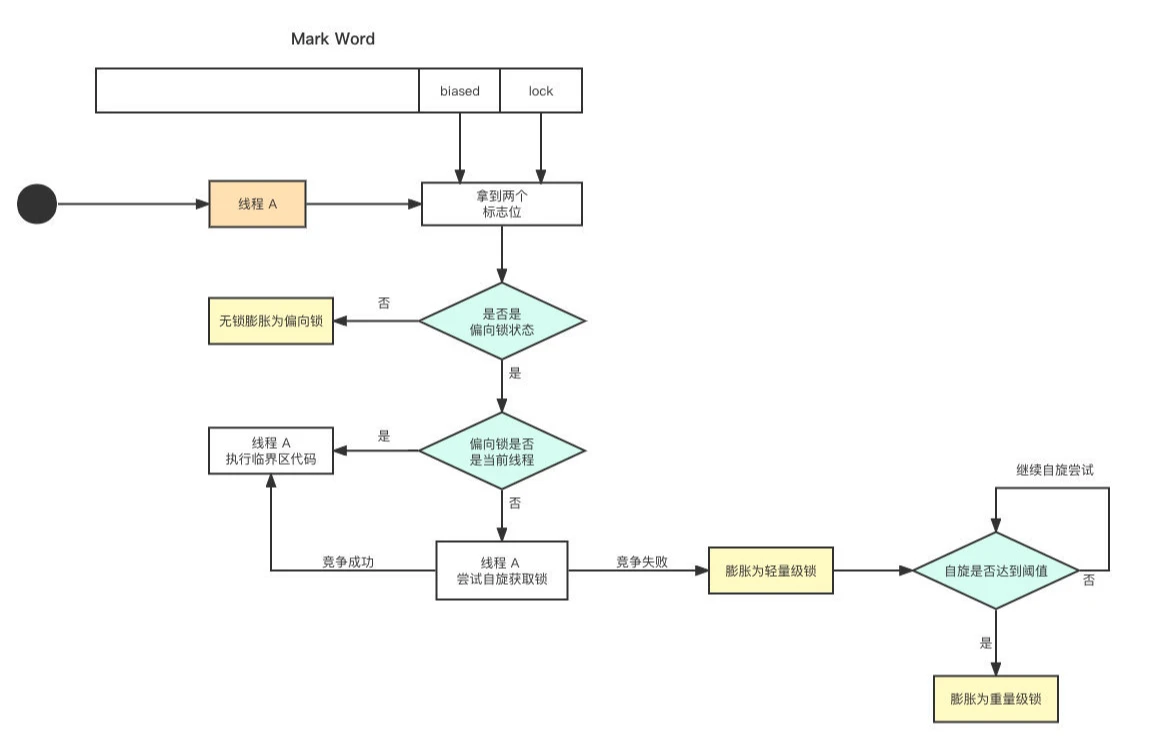
线程 A 进入 synchronized 开始竞争锁,JVM 会判断当前是否为偏向锁的状态,是则根据 Mark Word 中存储的线程 ID 判断当前线程 A 是否为持有偏向锁的线程,是则忽略 check,线程 A 直接执行临界区的代码
如果 Mark Word 中的线程 ID 不是线程 A,则会通过自选尝试获取锁,如果获取成功,就将 Mark Word 中的线程 ID 改为线程 A;如果获取失败,则会马上撤销自旋锁,膨胀为轻量级锁
后续的竞争线程都会通过自旋锁来尝试获取锁,如果自旋成功,那么锁的状态仍然是轻量级锁,如果竞争失败,锁就会膨胀为重量级锁,后续等待的竞争线程都会被阻塞
锁消除
属于编译器对锁的优化,JIT 编译器在动态编译同步块时,会使用逃逸分析技术,判断同步块的锁对象是否只能被一个对象访问,没有发布到其他线程,如果确认没有“逃逸”,JIT 编译器就不会生成 synchronized 对应的锁申请和释放的机器码,就消除了锁的使用
锁粗化
JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程反复申请、释放同一个锁所带来的性能开销
Java15 废弃偏向锁
受益于偏向锁的应用程序,往往是使用了早期 Java 集合 API 的程序(JDK1.1),这些 API(HashTable、Vector) 每次访问时都进行同步,JDK1.2 引入了针对单线程场景的非同步集合(HashMap、ArrayList),JDK1.5 针对多线程场景推出了性能更高的并发数据结构。这意味着如果使用较新的类,由于不必要同步而受益于偏向锁的应用程序可能会有很大的性能提高
此外,围绕线程池队列和工作线程构建的应用程序,性能通常在禁用偏向锁的情况下变得更好
偏向锁为同步系统引入了许多复杂的代码,并且对 HotSpot 的其他组件产生了影响,这种复杂性已经成为理解代码的障碍,也阻碍了对同步系统进行重构,因此希望禁用、废弃并最终删除偏向锁