HashMap
HashMap 核心知识
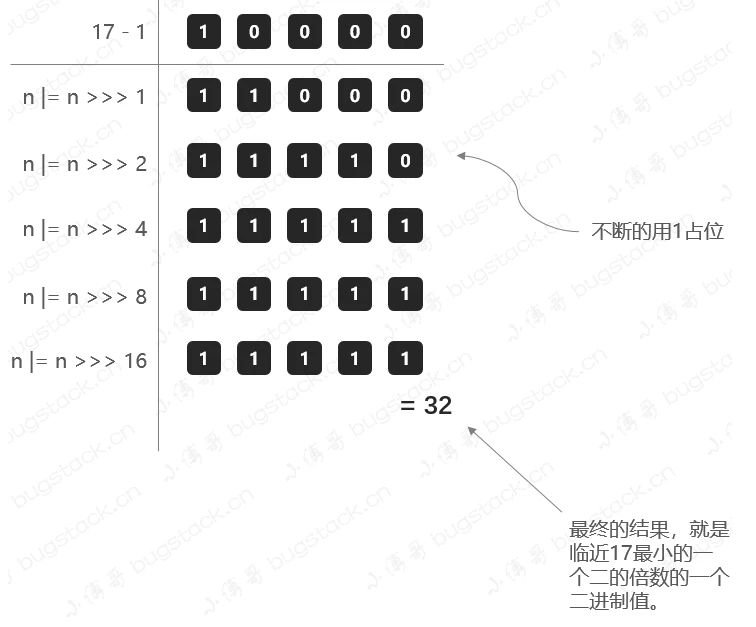
- HashMap 中定义的数组长度需为 2 的 N 次方,这样的数组长度才会出现一个除高位都是 1 的特征值(例如 0111),用于更好的实现散列
- 扰动函数: 增加随机性,让数据元素更加均衡的散列,减少碰撞
- 计算方式:
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);,把哈希值右移 16 位(正好是自己长度的一半),与原哈希值进行异或运算,混合了原哈希值中的高位的低位,增大了随机性
- 散列的作用: 较少 hash 的碰撞,让数据存放和获取的效率更佳
- 计算方式:
- 初始化容量:
- 负载因子: 决定 HashMap 进行扩容的数据量阈值,默认值 0.75,在希望使用更多空间换取时间时,可以缩小负载因子,减少碰撞
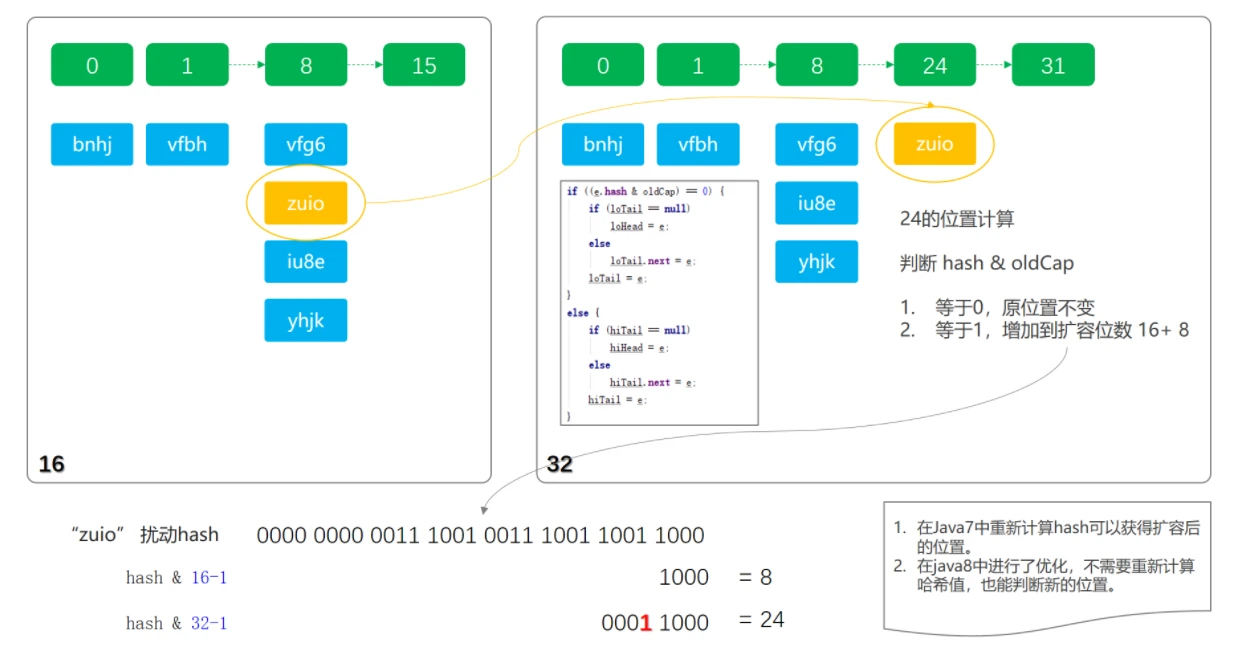
- 扩容元素拆分: JDK1.7 之前需要重新计算哈希值,在 JDK1.8 之后,将原哈希值与扩容新增出来的长度(16)进行&运算,如果不为 0,则新增的位置是在原来位置上加上长度(16)
- 数据迁移:
HashMap 源码分析
插入
- 插入
- 进行哈希值扰动,获取一个新的哈希值,
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); - 判断 tab(桶数组)是否为空或者长度为 0,如果是则进行扩容操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; - 根据哈希值计算下标,进行插入或者覆盖,
tab[i = (n - 1) & hash]) - 判断 tab[i]是否为树节点,是则向树中插入节点,否则向链表中插入数据
- 如向链表插入数据,需判断链表长度,如果大于等于 8 则需要把链表转换为红黑树,
treeifyBin(tab, hash); - 所有元素处理完成后,判断是否超过阈值,超过则进行扩容,
threshold - treeifyBin: 一个链表转树的方法,但不是所有的链表长度为 8 后都会转成树,还需要判断存放 key 值的数组桶长度(MIN_TREEIFY_CAPACITY)是否小于 64,如果小于则需要进行扩容,扩容后链表上的数据会被拆分散列到相应的桶节点上,也就把链表长度缩短了
- 进行哈希值扰动,获取一个新的哈希值,
- JDK1.8 HashMap的put方法源码
- 扩容机制: HashMap基于数组+链表和红黑树实现,但用于存放Key值的数组桶长度是固定的,由初始化决定
HashMap扩容代码- 扩容时计算出新的newCap、newThr,newCap是新的数组长度(Capacity),newThr是新的阈值(Threshold)
- newCap用于创建新的数组桶,
new Node[newCap] - 扩容后,原HashMap中因哈希碰撞存放成链表和红黑树的元素,都需要进行拆分存放到新的位置中
- 链表树化: JDK1.8以前采用链表方式存放发生哈希碰撞的元素,链表定位数据时间复杂度为O(n),链表越长性能越差,JDK1.8中把过长链表优化为自平衡的红黑树结构,以此让定位元素的时间复杂度优化近似于O(logN),优化阈值为8个
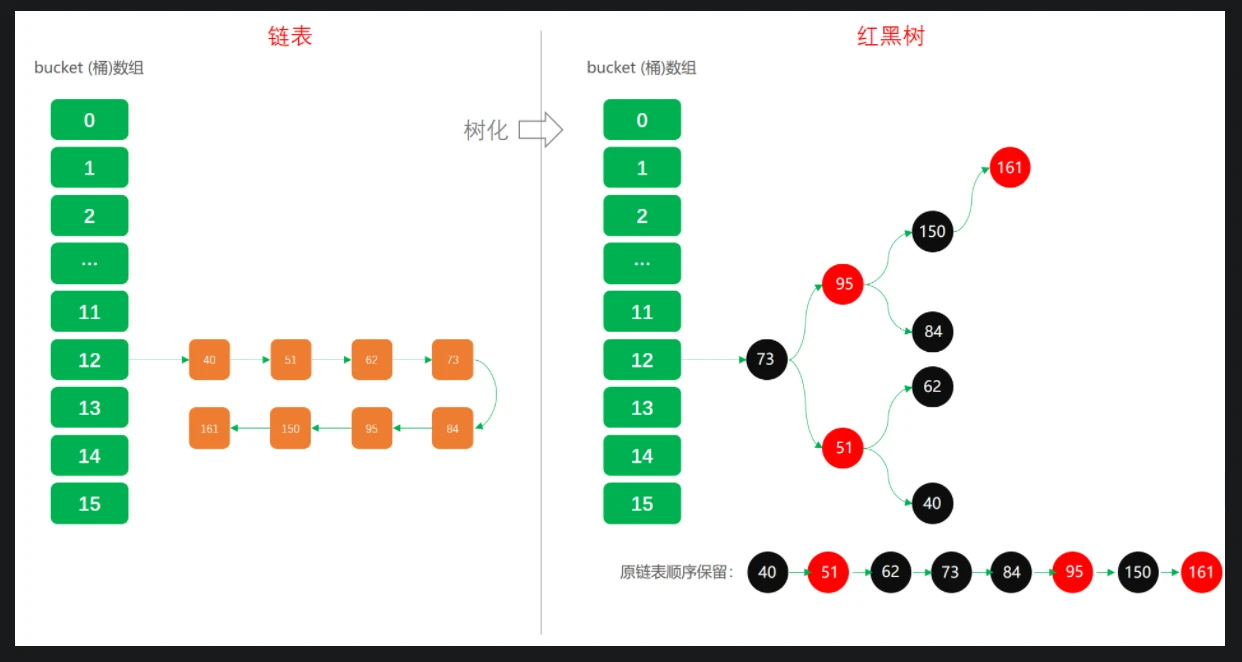
链表树化源码- 链表树化的条件: 链表长度>=8、桶容量>=64,否则进行扩容而非树化
- 链表树化过程中先由链表转换为树节点,此时树可能不是一颗平衡树,同时在树转换过程中会记录链表的顺序,
tl.next = p(方便后续扩容时进行树转链表和拆分) - 链表树化完成后,再进行红黑树的转换
- 红黑树转链: 在链表转树过程中,记录了原有链表的顺序,因此在红黑树转链的时候,直接把TreeNode转换为Node即可
HashMap-红黑树转链源码
查找
- 查找流程图
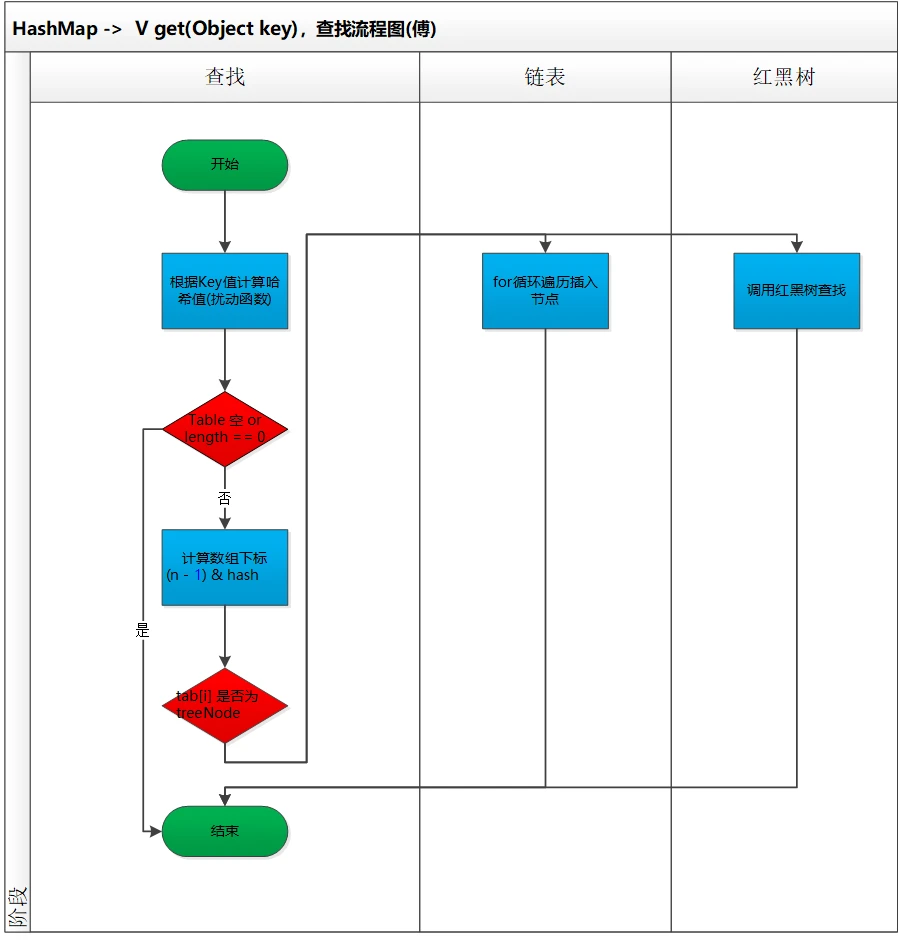
- 查找源码
- 使用扰动函数计算哈希值
- 计算数组下标,
tab[(n - 1) & hash]) - 确定了桶数组下标位置后,对红黑树和链表进行查找/遍历
删除
遍历
- 分链表和红黑树两种情况
- HashCode 为什么使用 31 作为乘数: 使用 31 作为乘数计算出的 Hash 值碰撞概率统计和 Hash 值散列分布最优